Si vous travaillez en affaires réglementaires ou en qualité dans le dispositif médical ou la pharma, un détail décide si une réponse est exploitable : l'édition. ISO 13485, ISO 14971, ISO 14155, IEC 62304 et les lignes directrices ICH sont toutes révisées, et citer une édition remplacée dans une soumission ou un audit n'est pas une petite erreur, c'est un écart. Demandez à une IA quelle édition est en vigueur, ce que la dernière révision des bonnes pratiques cliniques a changé, ou quel guide couvre les dispositifs à base d'IA et d'apprentissage automatique : elle répond avec aisance en citant l'édition sur laquelle elle a été entraînée, qui a peut-être été retirée.
Les modèles raisonnent parfaitement bien sur les normes. Ce qui leur fait défaut, c'est la portée : un modèle généraliste ne peut pas savoir quelle édition est en vigueur aujourd'hui. Donnez-lui le texte à jour, et il cesse de deviner.
Ce texte, c'est ce qu'Obsidian fournit, en profondeur sur les normes mondiales des sciences de la vie. Nous avons soumis les modèles à des centaines de tâches complexes couvrant les normes medtech ISO et IEC, les lignes directrices ICH et les guides IMDRF, chacune traitée par le modèle seul puis connecté à Obsidian.
L'IA est imprécise pour le travail réglementaire en sciences de la vie
Seuls, les modèles obtiennent en moyenne 52 sur 100. Connectez-les à Obsidian et la moyenne grimpe à 96. Le meilleur duo, gpt-5.5, atteint 97.5. Les modèles n'ont pas changé entre ces deux chiffres. Seules les données placées devant eux ont changé.
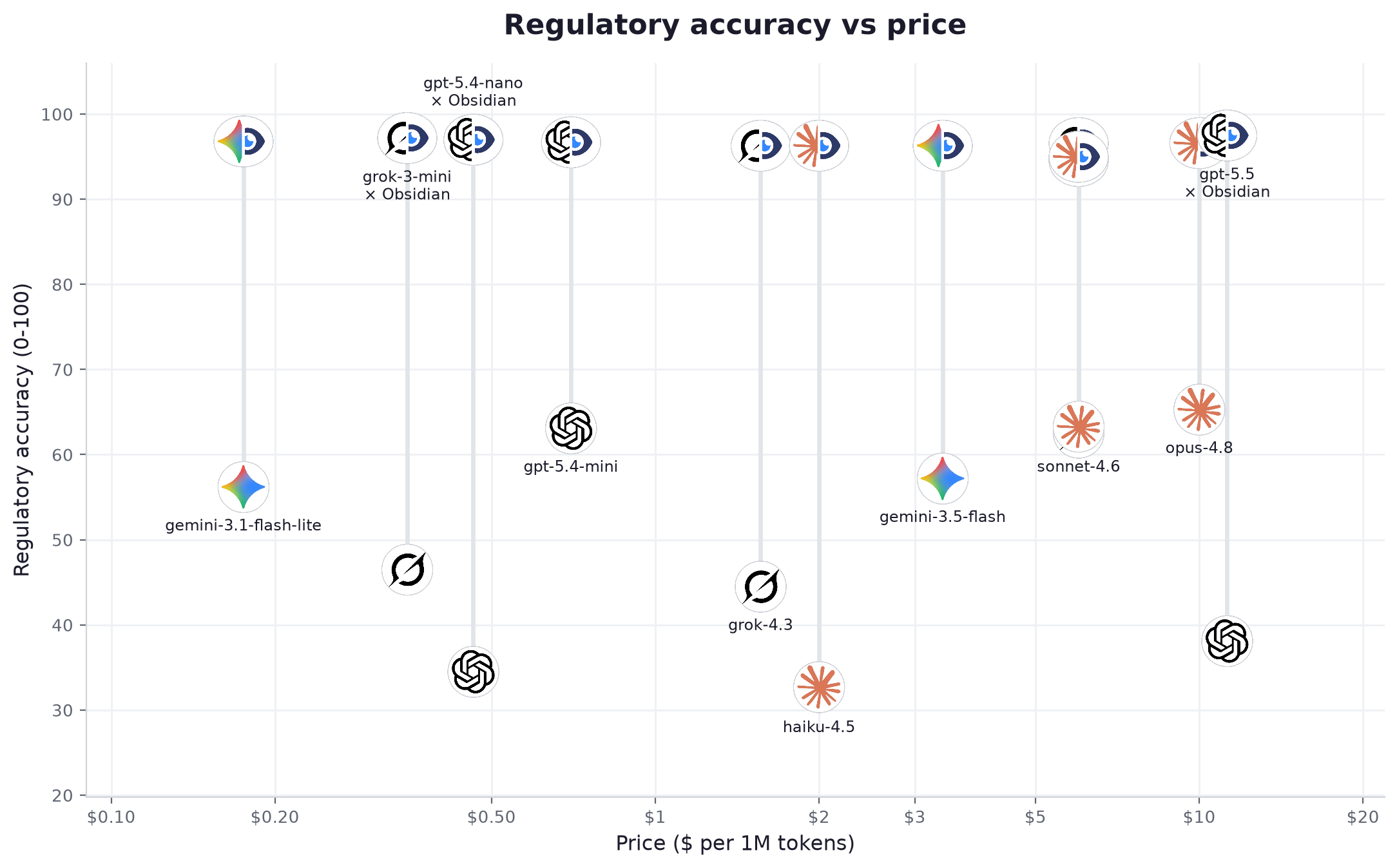
Les sciences de la vie sont le cas le plus net de tout ce benchmark en faveur d'une couche de données : les éditions bougent constamment, et un modèle qui travaille de mémoire cite celle qu'il a apprise plutôt que celle en vigueur. C'est exactement là qu'une soumission se retrouve bloquée. gemini-3.1-flash-lite, à $0.175 par million de tokens, passe de 56 à 97 une fois connecté, dans la bande des modèles plusieurs fois plus chers que lui. Un modèle léger connecté à Obsidian a battu un modèle frontière répondant seul dans 16 confrontations directes sur 16 sur le jeu sciences de la vie.
L'IA ne peut pas vous indiquer la norme officielle
Ici, l'édition est la réponse. Connectée à Obsidian, une réponse arrive avec la norme, son édition en vigueur, l'organisme émetteur et un lien direct. Seul, le modèle vous donne une citation plausible, souvent la mauvaise édition, à vérifier vous-même. Pour une revue par un organisme notifié ou une soumission réglementaire, la différence entre l'édition en vigueur et une édition retirée est la différence entre un dossier défendable et un écart.
Une réponse accompagnée de sa source tier-0 est une réponse que vous pouvez transmettre à un auditeur sans la revérifier. C'est la différence entre un brouillon imaginé par un modèle et une obligation sur laquelle vous pouvez agir.
L'IA hallucine
Nous avons décomposé chaque réponse en affirmations factuelles individuelles et vérifié chacune face à la source officielle. L'écart entre les deux chiffres d'affirmations fondées ci-dessus correspond au type d'erreur dangereux qui disparaît, sur un terrain où une seule mauvaise édition compromet une soumission. Le reliquat non fondé est du contexte ajouté, pas des références inventées.
Les données complètes, pour les puristes
Chaque modèle, dans les deux conditions. « Seul » désigne le modèle sans couche de données ; « avec Obsidian » désigne le même modèle connecté. La précision est un score de 0 à 100 attribué par un juge en aveugle face à une vérité terrain vérifiée par des humains. « Affirmations fondées » est la part des affirmations factuelles atomiques de la réponse qui remontent à la source officielle, seul puis avec Obsidian.
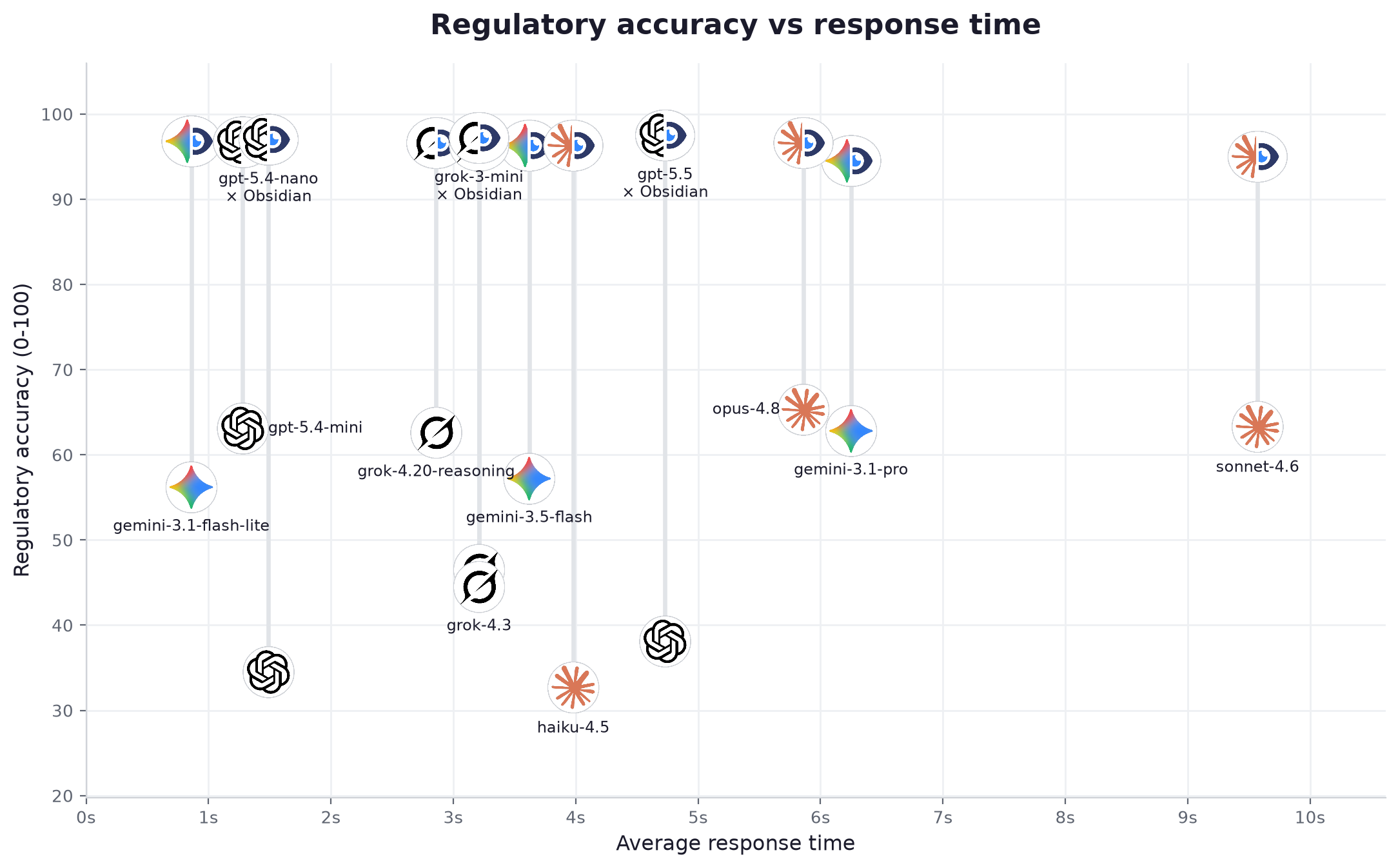
| # | Modèle | Fournisseur | Niveau | Préc. seul | Préc. + Obsidian | Gain | Cite la source | Statut correct | Affirmations fondées (seul → +Obs) | Latence | Vitesse | Prix /1M | Coût / question |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gpt-5.5 | OpenAI | avancé | 38.1 | 97.5 | +59.4 | 96% | 100% | 42% → 98% | 4.73s | 49 tok/s | $11.25 | $0.026259 |
| 2 | grok-3-mini | xAI | léger | 46.5 | 97.2 | +50.7 | 99% | 100% | 34% → 94% | 3.21s | 136 tok/s | $0.35 | $0.001342 |
| 3 | gpt-5.4-nano | OpenAI | léger | 34.5 | 97.0 | +62.5 | 97% | 100% | 24% → 98% | 1.49s | 88 tok/s | $0.463 | $0.000922 |
| 4 | gemini-3.1-flash-lite | léger | 56.2 | 96.8 | +40.6 | 98% | 100% | 30% → 98% | 0.86s | 139 tok/s | $0.175 | $0.000469 | |
| 5 | gpt-5.4-mini | OpenAI | intermédiaire | 63.1 | 96.7 | +33.6 | 97% | 100% | 38% → 95% | 1.28s | 87 tok/s | $0.7 | $0.001685 |
| 6 | grok-4.20-reasoning | xAI | avancé | 62.6 | 96.6 | +34.0 | 96% | 100% | 30% → 96% | 2.86s | 226 tok/s | $6.0 | $0.021106 |
| 7 | opus-4.8 | Anthropic | avancé | 65.3 | 96.6 | +31.3 | 96% | 100% | 28% → 93% | 5.86s | 69 tok/s | $10.0 | $0.039476 |
| 8 | gemini-3.5-flash | intermédiaire | 57.2 | 96.3 | +39.1 | 99% | 100% | 34% → 98% | 3.62s | 183 tok/s | $3.375 | $0.012549 | |
| 9 | grok-4.3 | xAI | intermédiaire | 44.5 | 96.3 | +51.8 | 98% | 100% | 32% → 97% | 3.21s | 132 tok/s | $1.562 | $0.005775 |
| 10 | haiku-4.5 | Anthropic | léger | 32.7 | 96.3 | +63.6 | 98% | 100% | 22% → 90% | 3.98s | 64 tok/s | $2.0 | $0.005482 |
| 11 | sonnet-4.6 | Anthropic | intermédiaire | 63.3 | 95.0 | +31.7 | 96% | 100% | 26% → 85% | 9.57s | 42 tok/s | $6.0 | $0.019201 |
| 12 | gemini-3.1-pro | avancé | 62.8 | 94.5 | +31.7 | 92% | 100% | 42% → 98% | 6.25s | 107 tok/s | $6.0 | $0.020789 |
Les sciences de la vie affichent le plus grand écart entre un modèle qui travaille de mémoire et un modèle qui lit la norme en vigueur, exactement là où une couche de données maintenue prouve sa valeur.
Comment nous avons mesuré
- L'ensemble complet des modèles d'Anthropic, OpenAI, Google et xAI.
- Des centaines de tâches complexes en sciences de la vie couvrant les normes medtech ISO et IEC (qualité, risque, clinique, logiciel, biocompatibilité), les lignes directrices ICH et les guides IMDRF, chacune reliée à sa source officielle et à son édition en vigueur.
- Deux conditions : le modèle seul, puis connecté à Obsidian.
- Un juge en aveugle note chaque réponse ; les affirmations fondées proviennent d'une vérification distincte, affirmation par affirmation, face à la source officielle.
Mettez la bonne édition de chaque norme derrière votre IA
Connectez Obsidian à l'IA que vous utilisez déjà et chaque réponse sur les normes revient avec l'édition en vigueur et l'organisme émetteur. Offre gratuite, installation en deux minutes.
Découvrir la couche de données ObsidianCe que cela change
Pour les équipes réglementaires et qualité du dispositif médical et de la pharma, l'assistant que vous utilisez déjà, alimenté par des données vérifiées, cesse de citer des éditions retirées et se met à répondre avec la norme et l'édition réellement en vigueur, si bien qu'un relecteur peut s'y fier dans une soumission. Le contexte est ici : les données réglementaires tier-0 et l'intelligence réglementaire agentique. Les résultats complets toutes industries confondues sont dans le benchmark d'IA réglementaire. Pour le tester sur vos propres questions, connectez la couche de données réglementaires Obsidian.