Posez une question réglementaire à une IA : la réponse arrive vite, fluide et sûre d'elle. Puis vous la vérifiez : un numéro de règlement qui n'existe pas, une édition en retard de deux versions, une règle citée comme contraignante alors qu'elle n'est encore qu'un projet. Après quelques expériences de ce genre, le verdict semble évident : l'IA n'est pas prête pour le travail réglementaire.
C'est le mauvais verdict. Les modèles que chacun utilise déjà sont parfaitement capables de raisonnement réglementaire. Ce qui leur fait défaut, ce n'est pas l'intelligence, c'est l'accès : un modèle généraliste répond à partir d'un instantané figé du web ouvert, sans aucun moyen d'ouvrir le texte réel d'un règlement ni de savoir s'il est en vigueur aujourd'hui. Donnez-lui ce texte, et il cesse de deviner.
Ce texte, c'est ce qu'apporte Obsidian : une couche de données réglementaires vérifiées, de niveau tier-0, conçue pour être interrogée par une IA. Pour mesurer ce qu'elle change, nous avons soumis 12 modèles largement utilisés à des centaines de tâches réglementaires complexes et précises couvrant l'ESG, la chimie et les sciences de la vie, chacune traitée deux fois. Une fois seul. Une fois connecté à Obsidian. Les trois chiffres ci-dessous résument toute l'histoire.
L'IA est imprécise pour le travail réglementaire
Seuls, les douze modèles obtiennent en moyenne 58 sur 100. Connectez-les à Obsidian et la moyenne grimpe à 94. Les modèles n'ont pas changé entre ces deux chiffres. Seules les données mises devant eux ont changé. Le gain se vérifie dans chaque domaine : la chimie passe de 53 à 95, les sciences de la vie de 52 à 96, l'ESG de 72 à 90. Vous n'achetez plus la précision avec le modèle ; vous la lui donnez avec les données.
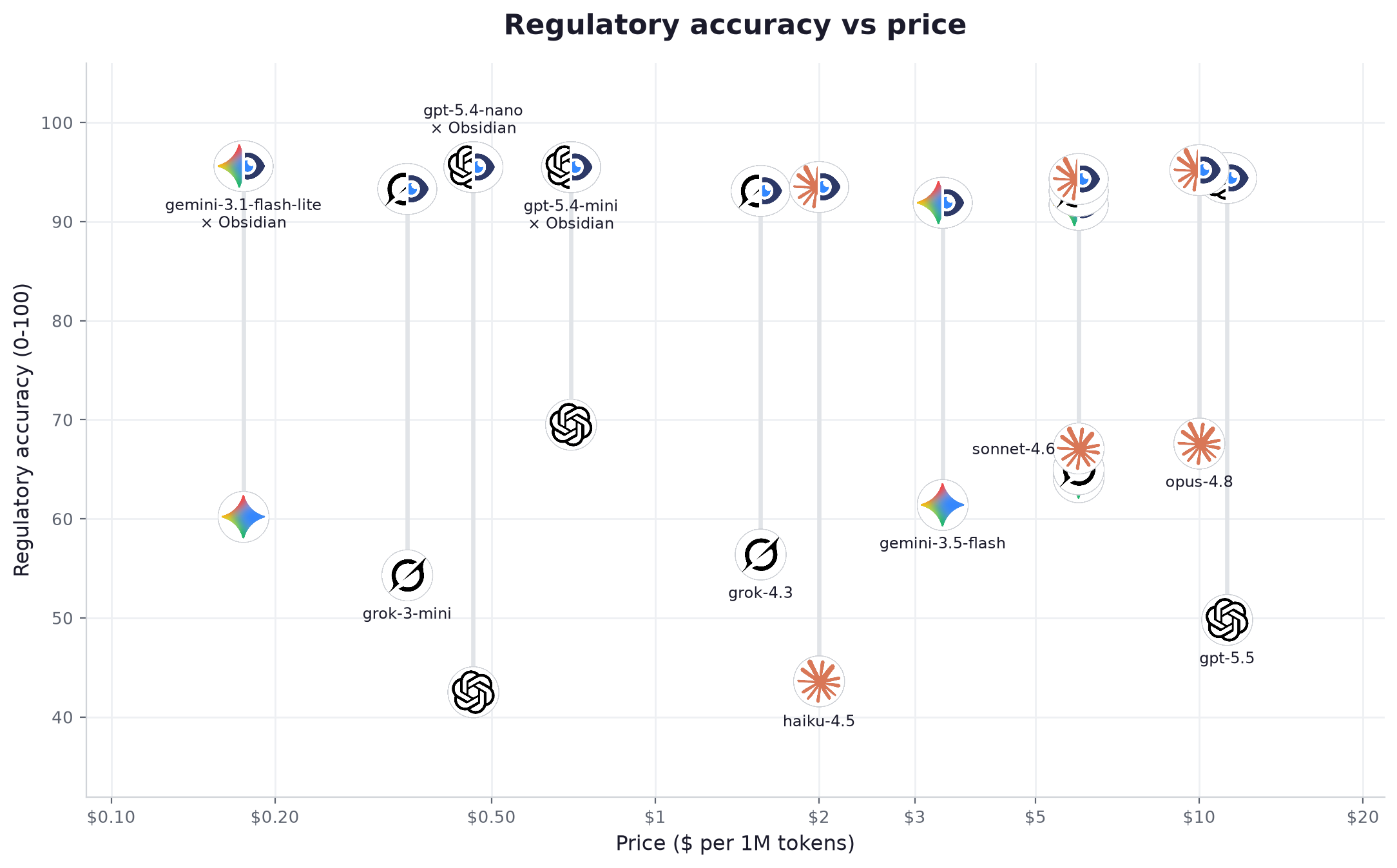
Le signal le plus net se trouve en bas de l'axe des prix. gemini-3.1-flash-lite, à $0.175 par million de tokens, passe de 60 à 96 une fois connecté : le meilleur score du tableau, devant des modèles plusieurs fois plus chers. Un modèle de gamme légère connecté à Obsidian a battu un modèle frontière répondant seul dans 16 confrontations sur 16. Sur le travail réglementaire, l'accès prime sur la puissance brute, et l'accès est exactement ce qu'ajoute une couche de données.
L'IA ne sait pas vous renvoyer à la source officielle
La précision n'est que la moitié du sujet. Une réponse connectée ne se contente pas de tomber sur la bonne règle, elle montre ses justificatifs : l'instrument, sa référence et son édition exactes, le statut juridique et un lien direct vers le document officiel, souvent le PDF source. Un modèle brut vous donne une citation d'apparence plausible qu'il vous faut ensuite vérifier vous-même, quand elle existe. La réponse connectée arrive déjà vérifiable, et c'est précisément ce dont une équipe conformité a besoin.
Une réponse accompagnée de sa source tier-0 est une réponse que vous pouvez transmettre à un auditeur sans la revérifier. C'est la différence entre un brouillon imaginé par un modèle et une obligation sur laquelle vous pouvez agir.
L'IA hallucine
Pour le mesurer précisément, nous avons décomposé chaque réponse en affirmations factuelles individuelles et vérifié chacune contre la source officielle, plutôt que de nous fier à un simple verdict binaire. L'écart entre les deux chiffres d'ancrage ci-dessus correspond à l'erreur la plus dangereuse, désormais éliminée : l'affirmation assurée qui ne repose sur rien. La part non ancrée restante n'est pas faite de citations inventées, c'est du contexte supplémentaire que le modèle ajoute autour de la source, et c'est pourquoi aucun modèle n'atteint un 100 parfait.
Les données complètes, pour les puristes
Chaque modèle, dans les deux conditions. « Seul » désigne le modèle sans couche de données ; « avec Obsidian » désigne le même modèle connecté. La précision est un score de 0 à 100 attribué par un juge en aveugle contre une vérité de référence vérifiée par des humains. « Affirmations ancrées » est la part des affirmations factuelles atomiques de la réponse qui remontent à la source officielle, seul puis avec Obsidian.
| # | Modèle | Fournisseur | Gamme | Préc. seul | Préc. + Obsidian | Gain | Cite la source | Statut correct | Affirmations ancrées (seul → +Obs) | Latence | Vitesse | Prix /1M | Coût / question |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gemini-3.1-flash-lite | légère | 60.2 | 95.6 | +35.4 | 96% | 100% | 25% → 98% | 0.82s | 130 tok/s | $0.175 | $0.000264 | |
| 2 | gpt-5.4-mini | OpenAI | intermédiaire | 69.5 | 95.5 | +26.0 | 96% | 100% | 38% → 96% | 1.25s | 84 tok/s | $0.7 | $0.000966 |
| 3 | gpt-5.4-nano | OpenAI | légère | 42.5 | 95.5 | +53.0 | 94% | 99% | 28% → 96% | 1.42s | 83 tok/s | $0.463 | $0.000551 |
| 4 | opus-4.8 | Anthropic | avancée | 67.6 | 95.2 | +27.6 | 96% | 100% | 24% → 89% | 4.86s | 69 tok/s | $10.0 | $0.024427 |
| 5 | gpt-5.5 | OpenAI | avancée | 49.8 | 94.4 | +44.6 | 96% | 100% | 44% → 96% | 4.89s | 42 tok/s | $11.25 | $0.0167 |
| 6 | sonnet-4.6 | Anthropic | intermédiaire | 67.1 | 94.3 | +27.2 | 96% | 100% | 24% → 81% | 7.89s | 46 tok/s | $6.0 | $0.012284 |
| 7 | haiku-4.5 | Anthropic | légère | 43.6 | 93.5 | +49.9 | 96% | 100% | 21% → 88% | 2.85s | 75 tok/s | $2.0 | $0.003326 |
| 8 | grok-3-mini | xAI | légère | 54.3 | 93.3 | +39.0 | 97% | 99% | 34% → 91% | 3.26s | 127 tok/s | $0.35 | $0.000822 |
| 9 | grok-4.20-reasoning | xAI | avancée | 65.0 | 93.1 | +28.1 | 94% | 99% | 28% → 93% | 2.82s | 222 tok/s | $6.0 | $0.016179 |
| 10 | grok-4.3 | xAI | intermédiaire | 56.4 | 93.1 | +36.7 | 95% | 99% | 32% → 93% | 3.21s | 126 tok/s | $1.562 | $0.003594 |
| 11 | gemini-3.5-flash | intermédiaire | 61.4 | 91.9 | +30.5 | 96% | 99% | 28% → 95% | 3.33s | 182 tok/s | $3.375 | $0.009259 | |
| 12 | gemini-3.1-pro | avancée | 64.2 | 91.7 | +27.5 | 92% | 99% | 33% → 97% | 6.09s | 108 tok/s | $6.0 | $0.017109 |
Toutes réponses confondues, un modèle de gamme légère connecté à Obsidian a battu chaque modèle frontière répondant seul. La part non ancrée des réponses connectées est du contexte ajouté au-delà de la source, pas des références fabriquées.
Comment nous avons mesuré
- 12 modèles d'Anthropic, OpenAI, Google et xAI, répartis entre gammes légère, intermédiaire et avancée.
- Des centaines de tâches réglementaires complexes et précises couvrant l'ESG (CSRD, les ESRS, la taxonomie de l'UE, SFDR, la CSDDD, le CBAM), la chimie (REACH, CLP, le SGH de l'ONU et les conventions de Stockholm, de Bâle et de Minamata) et les sciences de la vie (les normes medtech ISO et IEC, ICH, IMDRF), chacune reliée à sa source officielle tier-0. Les tâches hors du périmètre de couverture actuel d'Obsidian sont écartées, de sorte que le score mesure la qualité des réponses, pas l'étendue de la couverture.
- Deux conditions par tâche : le modèle seul, puis le même modèle connecté à Obsidian. Rien d'autre ne change.
- Un juge en aveugle note chaque réponse contre une vérité de référence vérifiée par des humains ; les affirmations ancrées proviennent d'une vérification séparée, affirmation par affirmation, contre la source officielle.
Faites de votre IA le modèle de la première ligne
Connectez Obsidian à Claude, ChatGPT, Gemini ou Cursor, et chaque réponse réglementaire revient avec sa source officielle, sa date et son statut juridique. Offre gratuite, installation en deux minutes.
Découvrir la couche de données ObsidianCe qu'il faut en retenir
Si vous travaillez déjà avec un assistant IA, la conclusion est concrète : vous n'avez pas besoin d'un modèle plus cher, et vous n'avez pas à vous contenter de suppositions. L'assistant que vous utilisez aujourd'hui, alimenté par des données réglementaires vérifiées, répond avec la précision d'un spécialiste et les justificatifs d'un auditeur. Le contexte complet est ici aussi : pourquoi l'IA hallucine sur les questions réglementaires, ce que sont les données réglementaires tier-0, et l'idée d'une intelligence réglementaire agentique. Les résultats par fournisseur et par secteur sont détaillés dans les éditions Claude, ChatGPT, ESG, chimie et sciences de la vie. Pour la tester sur vos propres questions, connectez la couche de données réglementaires Obsidian.