Wenn Sie in Regulatory Affairs oder im Qualitätsmanagement für Medizinprodukte oder Pharma arbeiten, entscheidet ein Detail darüber, ob eine Antwort brauchbar ist: die Ausgabe. ISO 13485, ISO 14971, ISO 14155, IEC 62304 und die ICH-Leitlinien werden alle überarbeitet, und eine ersetzte Ausgabe in einer Einreichung oder einem Audit zu zitieren ist kein kleiner Ausrutscher, sondern eine Abweichung. Fragen Sie eine KI, welche Ausgabe aktuell gilt, was die letzte Revision der guten klinischen Praxis geändert hat oder welche Leitlinie KI- und Machine-Learning-Produkte abdeckt: Sie antwortet flüssig mit der Ausgabe, mit der sie trainiert wurde, und die kann bereits zurückgezogen sein.
Die Modelle argumentieren über die Normen völlig souverän. Was ihnen fehlt, ist der Zugriff: Ein generalistisches Modell kann nicht wissen, welche Ausgabe heute in Kraft ist. Geben Sie ihm den aktuellen Text, und es hört auf zu raten.
Genau diesen Text liefert Obsidian, mit Tiefe bei den globalen Life-Sciences-Normen. Wir haben die Modelle durch Hunderte komplexer Aufgaben zu den ISO- und IEC-Medtech-Normen, den ICH-Leitlinien und den IMDRF-Leitfäden geschickt, jede einmal vom Modell allein und einmal mit Obsidian verbunden bearbeitet.
KI ist ungenau bei regulatorischer Arbeit in den Life Sciences
Allein erreichten die Modelle im Schnitt 52 von 100. Verbinden Sie sie mit Obsidian, steigt der Durchschnitt auf 96. Das beste Gespann, gpt-5.5, erreichte 97.5. Die Modelle haben sich zwischen diesen beiden Zahlen nicht verändert. Nur die Daten vor ihnen.
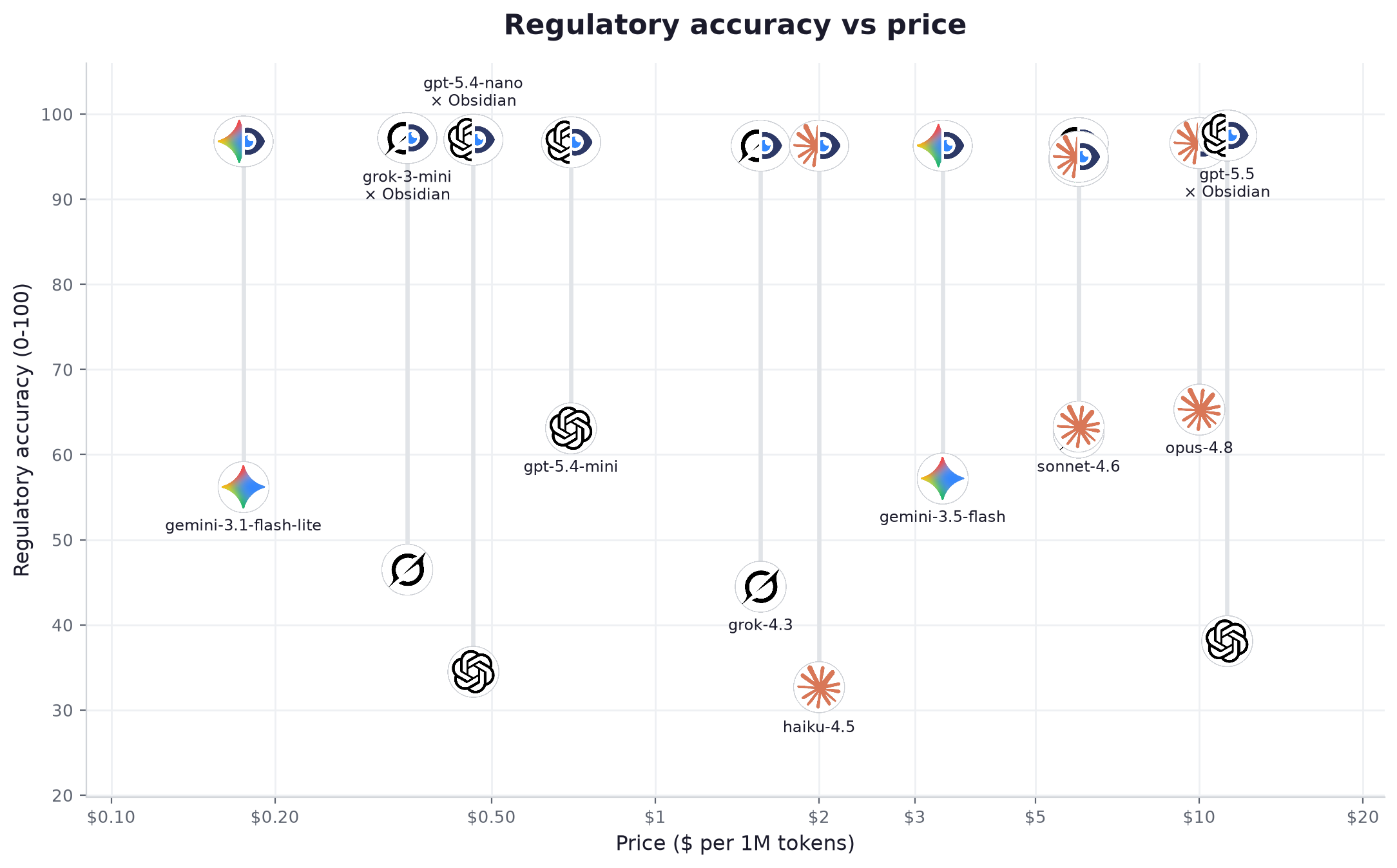
Die Life Sciences sind der deutlichste Fall für eine Datenschicht im gesamten Benchmark: Ausgaben ändern sich ständig, und ein Modell, das aus dem Gedächtnis arbeitet, zitiert die Ausgabe, die es gelernt hat, statt der geltenden. Genau an dieser einen Lücke bleibt eine Einreichung hängen. gemini-3.1-flash-lite, für $0.175 pro Million Tokens, klettert einmal verbunden von 56 auf 97, in die Liga von Modellen, die ein Vielfaches kosten. Ein leichtes Modell mit Obsidian schlug ein Frontier-Modell ohne Anbindung in 16 von 16 direkten Vergleichen auf dem Life-Sciences-Set.
KI kann Ihnen die offizielle Norm nicht nennen
Hier ist die Ausgabe die Antwort. Mit Obsidian verbunden kommt eine Antwort mit der Norm, ihrer aktuellen Ausgabe, der herausgebenden Organisation und einem direkten Link. Allein erhalten Sie ein plausibles Zitat, oft die falsche Ausgabe, das Sie selbst prüfen müssen. Für eine Prüfung durch eine Benannte Stelle oder eine regulatorische Einreichung ist der Unterschied zwischen der aktuellen und einer zurückgezogenen Ausgabe der Unterschied zwischen einer verteidigbaren Akte und einer Abweichung.
Eine Antwort mit angehängter Tier-0-Quelle können Sie einem Auditor weiterleiten, ohne sie nachzuprüfen. Das ist der Unterschied zwischen einem Entwurf, den sich ein Modell ausgedacht hat, und einer Pflicht, nach der Sie handeln können.
KI halluziniert
Wir haben jede Antwort in ihre einzelnen Tatsachenaussagen zerlegt und jede gegen die offizielle Quelle geprüft. Die Lücke zwischen den beiden Belegquoten oben ist genau die gefährliche Fehlerart, die verschwindet, auf einem Feld, auf dem eine einzige falsche Ausgabe eine Einreichung untergräbt. Der nicht belegte Rest ist ergänzender Kontext, keine erfundenen Referenzen.
Die vollständigen Daten, für die Puristen
Jedes Modell, beide Bedingungen. "Allein" ist das Modell ohne Datenschicht; "mit Obsidian" ist dasselbe Modell verbunden. Die Genauigkeit ist ein Score von 0 bis 100, vergeben von einem blinden Bewertungsverfahren gegen eine von Menschen verifizierte Referenz. "Belegte Aussagen" ist der Anteil der atomaren Tatsachenaussagen der Antwort, die sich auf die offizielle Quelle zurückführen lassen, allein gegenüber mit Obsidian.
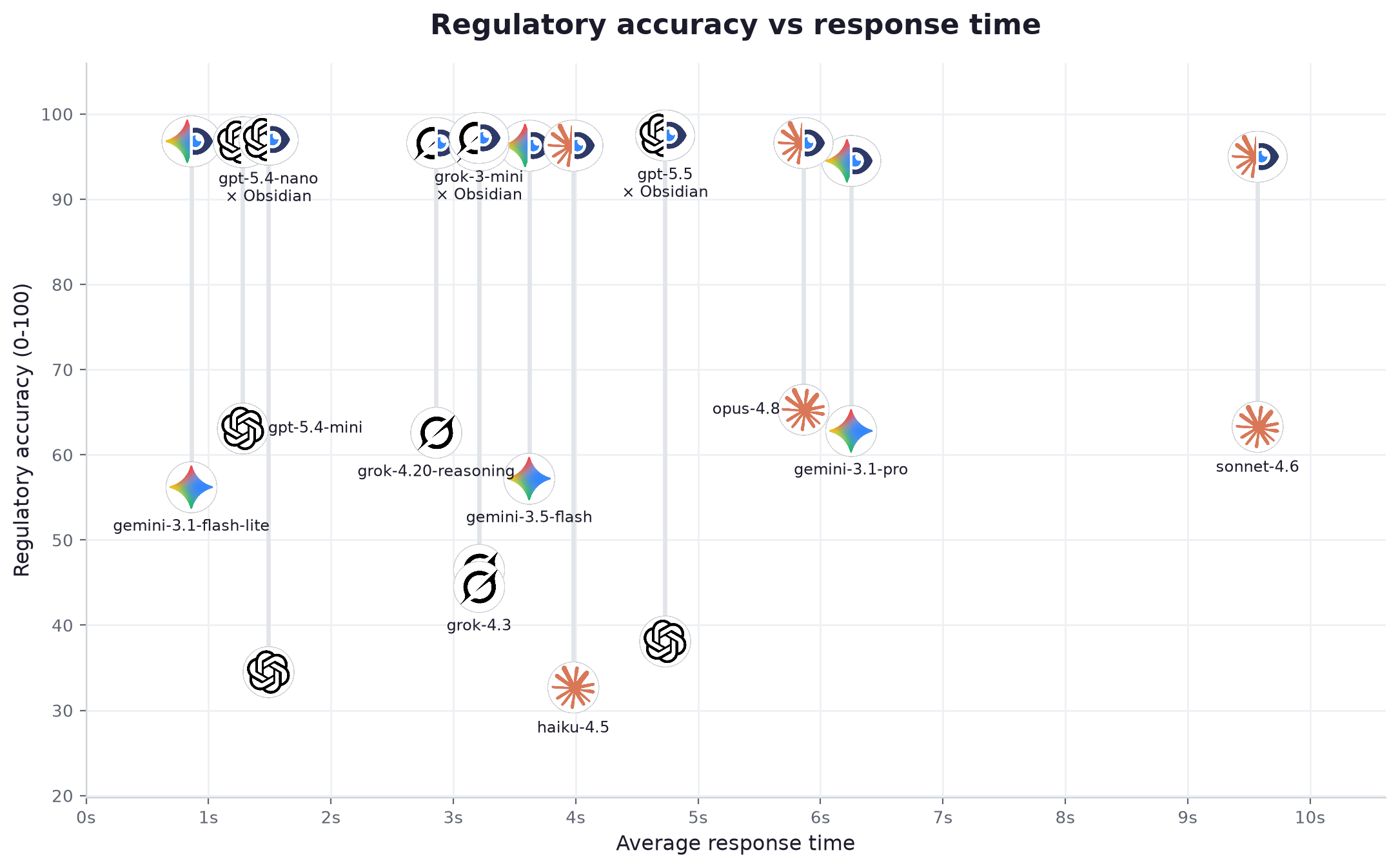
| # | Modell | Anbieter | Stufe | Gen. allein | Gen. + Obsidian | Zuwachs | Nennt Quelle | Status korrekt | Belegte Aussagen (allein → +Obs) | Latenz | Tempo | Preis /1M | Kosten / Frage |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gpt-5.5 | OpenAI | fortgeschritten | 38.1 | 97.5 | +59.4 | 96% | 100% | 42% → 98% | 4.73s | 49 tok/s | $11.25 | $0.026259 |
| 2 | grok-3-mini | xAI | leicht | 46.5 | 97.2 | +50.7 | 99% | 100% | 34% → 94% | 3.21s | 136 tok/s | $0.35 | $0.001342 |
| 3 | gpt-5.4-nano | OpenAI | leicht | 34.5 | 97.0 | +62.5 | 97% | 100% | 24% → 98% | 1.49s | 88 tok/s | $0.463 | $0.000922 |
| 4 | gemini-3.1-flash-lite | leicht | 56.2 | 96.8 | +40.6 | 98% | 100% | 30% → 98% | 0.86s | 139 tok/s | $0.175 | $0.000469 | |
| 5 | gpt-5.4-mini | OpenAI | mittel | 63.1 | 96.7 | +33.6 | 97% | 100% | 38% → 95% | 1.28s | 87 tok/s | $0.7 | $0.001685 |
| 6 | grok-4.20-reasoning | xAI | fortgeschritten | 62.6 | 96.6 | +34.0 | 96% | 100% | 30% → 96% | 2.86s | 226 tok/s | $6.0 | $0.021106 |
| 7 | opus-4.8 | Anthropic | fortgeschritten | 65.3 | 96.6 | +31.3 | 96% | 100% | 28% → 93% | 5.86s | 69 tok/s | $10.0 | $0.039476 |
| 8 | gemini-3.5-flash | mittel | 57.2 | 96.3 | +39.1 | 99% | 100% | 34% → 98% | 3.62s | 183 tok/s | $3.375 | $0.012549 | |
| 9 | grok-4.3 | xAI | mittel | 44.5 | 96.3 | +51.8 | 98% | 100% | 32% → 97% | 3.21s | 132 tok/s | $1.562 | $0.005775 |
| 10 | haiku-4.5 | Anthropic | leicht | 32.7 | 96.3 | +63.6 | 98% | 100% | 22% → 90% | 3.98s | 64 tok/s | $2.0 | $0.005482 |
| 11 | sonnet-4.6 | Anthropic | mittel | 63.3 | 95.0 | +31.7 | 96% | 100% | 26% → 85% | 9.57s | 42 tok/s | $6.0 | $0.019201 |
| 12 | gemini-3.1-pro | fortgeschritten | 62.8 | 94.5 | +31.7 | 92% | 100% | 42% → 98% | 6.25s | 107 tok/s | $6.0 | $0.020789 |
Die Life Sciences zeigen die größte Lücke zwischen einem Modell, das aus dem Gedächtnis arbeitet, und einem, das die geltende Norm liest, genau dort, wo eine gepflegte Datenschicht ihren Platz verdient.
Wie wir gemessen haben
- Das vollständige Modellset von Anthropic, OpenAI, Google und xAI.
- Hunderte komplexer Life-Sciences-Aufgaben zu den ISO- und IEC-Medtech-Normen (Qualität, Risiko, Klinik, Software, Biokompatibilität), den ICH-Leitlinien und den IMDRF-Leitfäden, jede mit ihrer offiziellen Quelle und der aktuellen Ausgabe verknüpft.
- Zwei Bedingungen: das Modell allein, und mit Obsidian verbunden.
- Eine blinde Bewertung benotet jede Antwort; die belegten Aussagen stammen aus einer separaten Prüfung, Aussage für Aussage, gegen die offizielle Quelle.
Stellen Sie die richtige Ausgabe jeder Norm hinter Ihre KI
Verbinden Sie Obsidian mit der KI, die Sie bereits nutzen, und jede Antwort zu Normen kommt mit der aktuellen Ausgabe und der herausgebenden Organisation zurück. Kostenlose Stufe, Einrichtung in zwei Minuten.
Die Obsidian-Datenschicht entdeckenWas das bedeutet
Für Regulatory- und Qualitätsteams in Medizintechnik und Pharma hört der Assistent, den Sie bereits nutzen, mit verifizierten Daten auf, zurückgezogene Ausgaben zu zitieren, und antwortet mit der Norm und der Ausgabe, die tatsächlich in Kraft sind, sodass sich ein Prüfer in einer Einreichung darauf verlassen kann. Der Hintergrund steht hier: Tier-0-Regulierungsdaten und agentische Regulatory Intelligence. Die vollständigen branchenübergreifenden Ergebnisse stehen im Regulatory-AI-Benchmark. Um es mit Ihren eigenen Fragen zu testen, verbinden Sie die Obsidian-Datenschicht für Regulierungsdaten.