Stellen Sie einer KI eine regulatorische Frage: die Antwort kommt schnell, flüssig und selbstsicher. Dann prüfen Sie sie: eine Verordnungsnummer, die nicht existiert, eine Ausgabe, die zwei Versionen zurückliegt, eine Regel, die als verbindlich zitiert wird, obwohl sie noch ein Entwurf ist. Nach genug solcher Erfahrungen scheint das Urteil klar: KI ist für regulatorische Arbeit nicht bereit.
Es ist das falsche Urteil. Die Modelle, die alle bereits nutzen, sind zu regulatorischem Denken durchaus fähig. Was ihnen fehlt, ist nicht Intelligenz, sondern Zugriff: ein generalistisches Modell antwortet aus einem eingefrorenen Abbild des offenen Webs, ohne jede Möglichkeit, den tatsächlichen Text einer Verordnung zu öffnen oder zu wissen, ob sie heute in Kraft ist. Geben Sie ihm diesen Text, und es hört auf zu raten.
Diesen Text liefert Obsidian: eine verifizierte regulatorische Datenschicht auf tier-0-Niveau, gebaut dafür, von einer KI abgefragt zu werden. Um zu messen, was sie verändert, haben wir 12 weit verbreitete Modelle durch Hunderte komplexer, präziser regulatorischer Aufgaben in den Bereichen ESG, Chemie und Life Sciences geschickt, jede zweimal bearbeitet. Einmal allein. Einmal mit Obsidian verbunden. Die drei Zahlen unten erzählen die ganze Geschichte.
KI ist für regulatorische Arbeit ungenau
Allein erreichten die zwölf Modelle im Schnitt 58 von 100. Verbinden Sie sie mit Obsidian, und der Durchschnitt steigt auf 94. Die Modelle haben sich zwischen diesen beiden Zahlen nicht verändert. Nur die Daten vor ihnen. Der Zuwachs zeigt sich in jedem Bereich: Chemie von 53 auf 95, Life Sciences von 52 auf 96, ESG von 72 auf 90. Sie kaufen Genauigkeit nicht mehr mit dem Modell ein; Sie geben sie ihm mit den Daten.
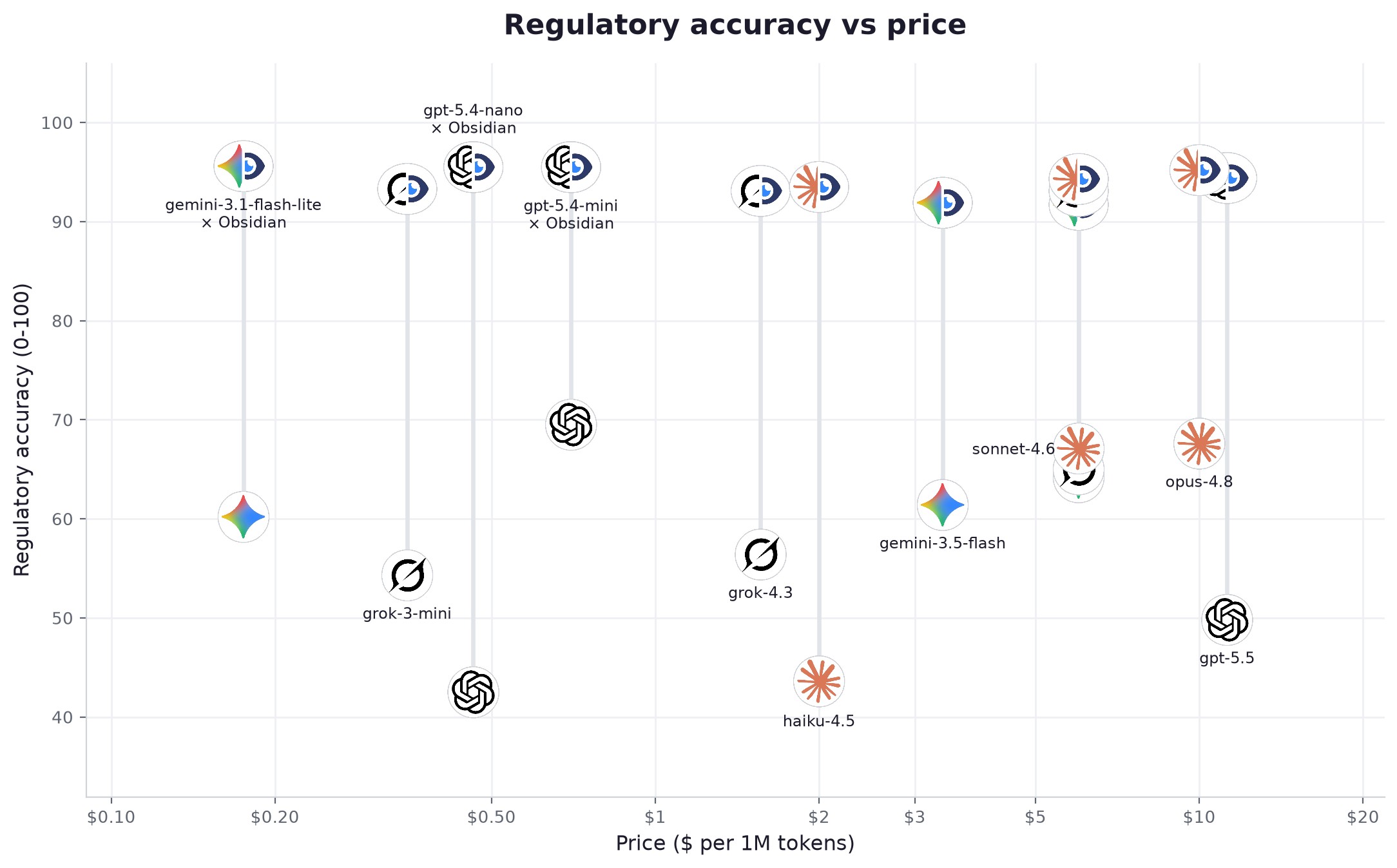
Das deutlichste Signal sitzt am unteren Ende der Preisachse. gemini-3.1-flash-lite, für $0.175 pro Million Tokens, klettert verbunden von 60 auf 96: der beste Wert der Tabelle, vor jedem Modell, das ein Vielfaches kostet. Ein Modell der leichten Klasse mit Obsidian schlug ein allein antwortendes Frontier-Modell in 16 von 16 direkten Vergleichen. Bei regulatorischer Arbeit schlägt Zugriff rohe Leistungsfähigkeit, und Zugriff ist genau das, was eine Datenschicht hinzufügt.
KI kann Sie nicht auf die offizielle Quelle verweisen
Genauigkeit ist nur die halbe Sache. Eine verbundene Antwort trifft nicht nur die richtige Regel, sie legt ihre Belege offen: das Instrument, seine exakte Referenz und Ausgabe, den Rechtsstatus und einen direkten Link zum offiziellen Dokument, oft zum Quell-PDF. Ein Modell ohne Anbindung liefert Ihnen ein plausibel wirkendes Zitat, das Sie anschließend selbst verifizieren müssen, falls es überhaupt existiert. Die verbundene Antwort kommt bereits überprüfbar an, und genau das braucht ein Compliance-Team.
Eine Antwort mit angehängter tier-0-Quelle können Sie an einen Auditor weiterleiten, ohne sie nachzuprüfen. Das ist der Unterschied zwischen einem Entwurf, den ein Modell sich ausgedacht hat, und einer Pflicht, nach der Sie handeln können.
KI halluziniert
Um das präzise zu messen, haben wir jede Antwort in ihre einzelnen Tatsachenaussagen zerlegt und jede gegen die offizielle Quelle geprüft, statt einem einzigen Ja-oder-Nein-Urteil zu vertrauen. Die Lücke zwischen den beiden Verankerungswerten oben ist die gefährliche Art von Fehler, die verschwindet: die selbstsichere Aussage ohne jede Grundlage. Der verbleibende nicht verankerte Anteil besteht nicht aus erfundenen Zitaten, sondern aus zusätzlichem Kontext, den ein Modell um die Quelle herum ergänzt, weshalb kein Modell eine glatte 100 erreicht.
Die vollständigen Daten, für die Puristen
Jedes Modell, beide Bedingungen. "Allein" ist das Modell ohne Datenschicht; "mit Obsidian" ist dasselbe Modell verbunden. Die Genauigkeit ist ein Wert von 0 bis 100, vergeben von einem blinden Gutachter gegen eine von Menschen verifizierte Referenzwahrheit. "Verankerte Aussagen" ist der Anteil der atomaren Tatsachenaussagen der Antwort, die sich auf die offizielle Quelle zurückführen lassen, allein gegenüber mit Obsidian.
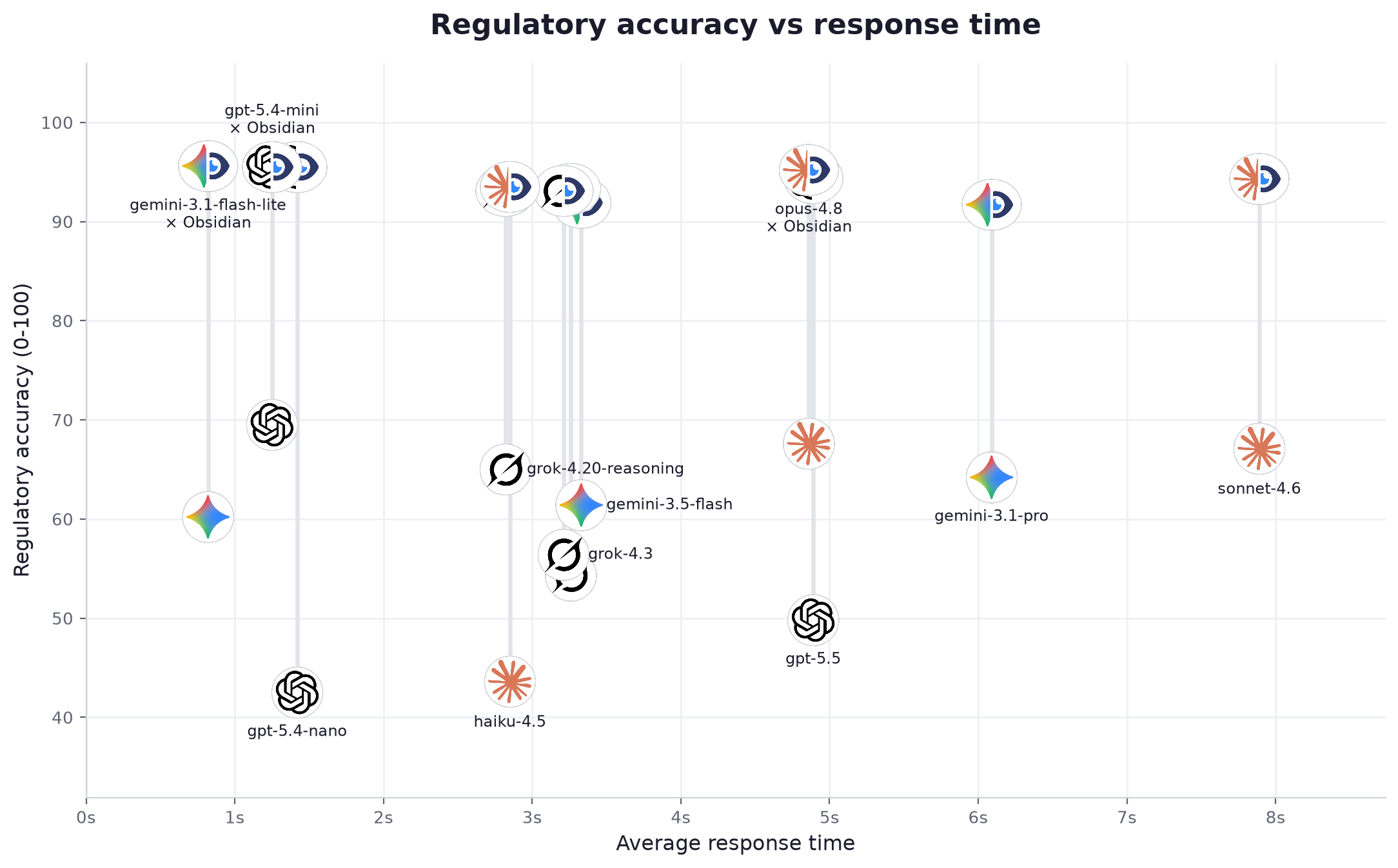
| # | Modell | Anbieter | Klasse | Gen. allein | Gen. + Obsidian | Zuwachs | Zitiert die Quelle | Status korrekt | Verankerte Aussagen (allein → +Obs) | Latenz | Tempo | Preis /1M | Kosten / Frage |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gemini-3.1-flash-lite | leicht | 60.2 | 95.6 | +35.4 | 96% | 100% | 25% → 98% | 0.82s | 130 tok/s | $0.175 | $0.000264 | |
| 2 | gpt-5.4-mini | OpenAI | mittel | 69.5 | 95.5 | +26.0 | 96% | 100% | 38% → 96% | 1.25s | 84 tok/s | $0.7 | $0.000966 |
| 3 | gpt-5.4-nano | OpenAI | leicht | 42.5 | 95.5 | +53.0 | 94% | 99% | 28% → 96% | 1.42s | 83 tok/s | $0.463 | $0.000551 |
| 4 | opus-4.8 | Anthropic | fortgeschritten | 67.6 | 95.2 | +27.6 | 96% | 100% | 24% → 89% | 4.86s | 69 tok/s | $10.0 | $0.024427 |
| 5 | gpt-5.5 | OpenAI | fortgeschritten | 49.8 | 94.4 | +44.6 | 96% | 100% | 44% → 96% | 4.89s | 42 tok/s | $11.25 | $0.0167 |
| 6 | sonnet-4.6 | Anthropic | mittel | 67.1 | 94.3 | +27.2 | 96% | 100% | 24% → 81% | 7.89s | 46 tok/s | $6.0 | $0.012284 |
| 7 | haiku-4.5 | Anthropic | leicht | 43.6 | 93.5 | +49.9 | 96% | 100% | 21% → 88% | 2.85s | 75 tok/s | $2.0 | $0.003326 |
| 8 | grok-3-mini | xAI | leicht | 54.3 | 93.3 | +39.0 | 97% | 99% | 34% → 91% | 3.26s | 127 tok/s | $0.35 | $0.000822 |
| 9 | grok-4.20-reasoning | xAI | fortgeschritten | 65.0 | 93.1 | +28.1 | 94% | 99% | 28% → 93% | 2.82s | 222 tok/s | $6.0 | $0.016179 |
| 10 | grok-4.3 | xAI | mittel | 56.4 | 93.1 | +36.7 | 95% | 99% | 32% → 93% | 3.21s | 126 tok/s | $1.562 | $0.003594 |
| 11 | gemini-3.5-flash | mittel | 61.4 | 91.9 | +30.5 | 96% | 99% | 28% → 95% | 3.33s | 182 tok/s | $3.375 | $0.009259 | |
| 12 | gemini-3.1-pro | fortgeschritten | 64.2 | 91.7 | +27.5 | 92% | 99% | 33% → 97% | 6.09s | 108 tok/s | $6.0 | $0.017109 |
Über alle Antworten hinweg schlug ein Modell der leichten Klasse mit Obsidian jedes allein antwortende Frontier-Modell. Der nicht verankerte Rest der verbundenen Antworten ist über die Quelle hinaus ergänzter Kontext, keine fabrizierten Referenzen.
Wie wir gemessen haben
- 12 Modelle von Anthropic, OpenAI, Google und xAI, verteilt über die Klassen leicht, mittel und fortgeschritten.
- Hunderte komplexer, präziser regulatorischer Aufgaben in ESG (CSRD, die ESRS, die EU-Taxonomie, SFDR, die CSDDD, CBAM), Chemie (REACH, CLP, das GHS der UN sowie die Übereinkommen von Stockholm, Basel und Minamata) und Life Sciences (die ISO- und IEC-Medtech-Normen, ICH, IMDRF), jede an ihre offizielle tier-0-Quelle gebunden. Aufgaben außerhalb des aktuellen Abdeckungsperimeters von Obsidian werden beiseitegelegt, sodass der Wert die Antwortqualität misst, nicht die Abdeckungsbreite.
- Zwei Bedingungen pro Aufgabe: das Modell allein, und dasselbe Modell mit Obsidian verbunden. Sonst ändert sich nichts.
- Ein blinder Gutachter bewertet jede Antwort gegen eine von Menschen verifizierte Referenzwahrheit; die verankerten Aussagen stammen aus einer separaten Prüfung, Aussage für Aussage, gegen die offizielle Quelle.
Machen Sie Ihre KI zum Modell in Zeile eins
Verbinden Sie Obsidian mit Claude, ChatGPT, Gemini oder Cursor, und jede regulatorische Antwort kommt mit ihrer offiziellen Quelle, ihrem Datum und ihrem Rechtsstatus zurück. Kostenloser Tarif, Einrichtung in zwei Minuten.
Die Obsidian-Datenschicht entdeckenWas das bedeutet
Wenn Sie bereits über einen KI-Assistenten arbeiten, ist die Folgerung konkret: Sie brauchen kein teureres Modell, und Sie müssen sich nicht mit Vermutungen abfinden. Der Assistent, den Sie heute nutzen, antwortet mit verifizierten regulatorischen Daten mit der Präzision eines Spezialisten und den Belegen eines Auditors. Der Hintergrund steht ebenfalls bereit: warum KI bei regulatorischen Fragen halluziniert, was tier-0-Regulierungsdaten sind, und die Idee der agentischen Regulatory Intelligence. Die Ergebnisse je Anbieter und Branche sind in den Ausgaben Claude, ChatGPT, ESG, Chemie und Life Sciences aufgeschlüsselt. Um es mit Ihren eigenen Fragen zu testen, verbinden Sie die regulatorische Datenschicht von Obsidian.