
Ask an AI a regulatory question and the answer comes back fast, fluent, and sure of itself. Then you check it: a regulation number that does not exist, an edition two versions out of date, a rule quoted as binding when it is still a draft. After enough of these, the verdict feels obvious: AI is not ready for regulatory work.
It is the wrong verdict. The models people already use are perfectly capable of regulatory reasoning. What fails them is not intelligence, it is reach: a general model answers from a frozen snapshot of the open web, with no way to open the actual text of a regulation or to know whether it is in force today. Hand it that text, and it stops guessing.
That text is what Obsidian supplies: a verified, tier-0 regulatory data layer built for an AI to query. To measure what it changes, we put 12 widely used models through hundreds of complex, precise regulatory tasks across ESG, chemicals and life sciences, each one handled twice. Once alone. Once connected to Obsidian. The three numbers below are the whole story.
AI is inaccurate for regulatory work
Alone, the twelve models averaged 58 out of 100. Connect them to Obsidian and the average climbs to 94. The models did not change between those two numbers. Only the data in front of them did. The lift holds in every domain: chemicals from 53 to 95, life sciences from 52 to 96, ESG from 72 to 90. You are no longer buying accuracy from the model; you are handing it the data.
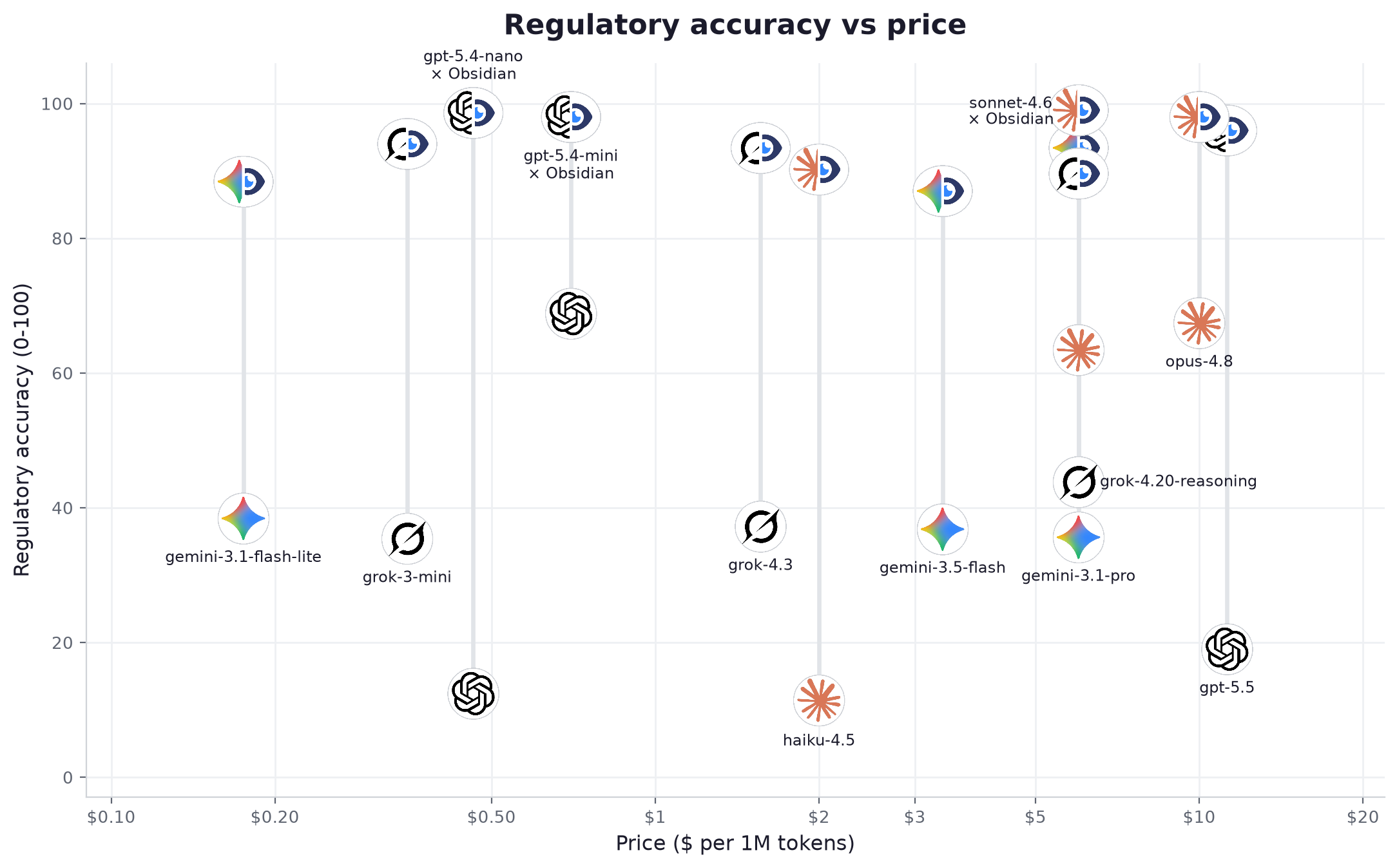
The clearest signal sits at the bottom of the price axis. gemini-3.1-flash-lite, at $0.175 per million tokens, climbs from 60 to 96 once connected, the top score in the table and ahead of every model many times its price. A light-tier model connected to Obsidian beat a frontier model answering alone in 16 of 16 head-to-head pairings. On regulatory work, reach beats raw capability, and reach is exactly what a data layer adds.
AI cannot point you to the official source
Accuracy is only half of it. A connected answer does not just land on the right rule, it shows its work: the instrument, its exact reference and edition, the legal status, and a direct link to the official document, often the source PDF. A raw model gives you a plausible-looking citation you then have to verify yourself, if it exists at all. The connected answer arrives already checkable, which is the part a compliance team actually needs.
An answer with the tier-0 source attached is one you can forward to an auditor without re-checking it. That is the difference between a draft a model imagined and an obligation you can act on.
AI hallucinates
To measure that precisely we broke every answer into its individual factual claims and checked each against the official source, rather than trusting a single yes-or-no verdict. The gap between the two grounded-claim numbers above is the dangerous kind of error removed: the confident statement with nothing behind it. The remaining ungrounded share is not invented citations, it is extra context a model adds around the source, which is why no model hits a clean 100.
The full data, for the purists
Every model, both conditions. "Alone" is the model with no data layer; "with Obsidian" is the same model connected. Accuracy is a 0 to 100 score from a blind judge against human-verified ground truth. "Grounded claims" is the share of the answer's atomic factual claims that trace back to the official source, alone versus with Obsidian.
| # | Model | Provider | Tier | Acc. alone | Acc. + Obsidian | Lift | Cites source | Status correct | Grounded claims (alone → +Obs) | Latency | Speed | Price /1M | Cost / question |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
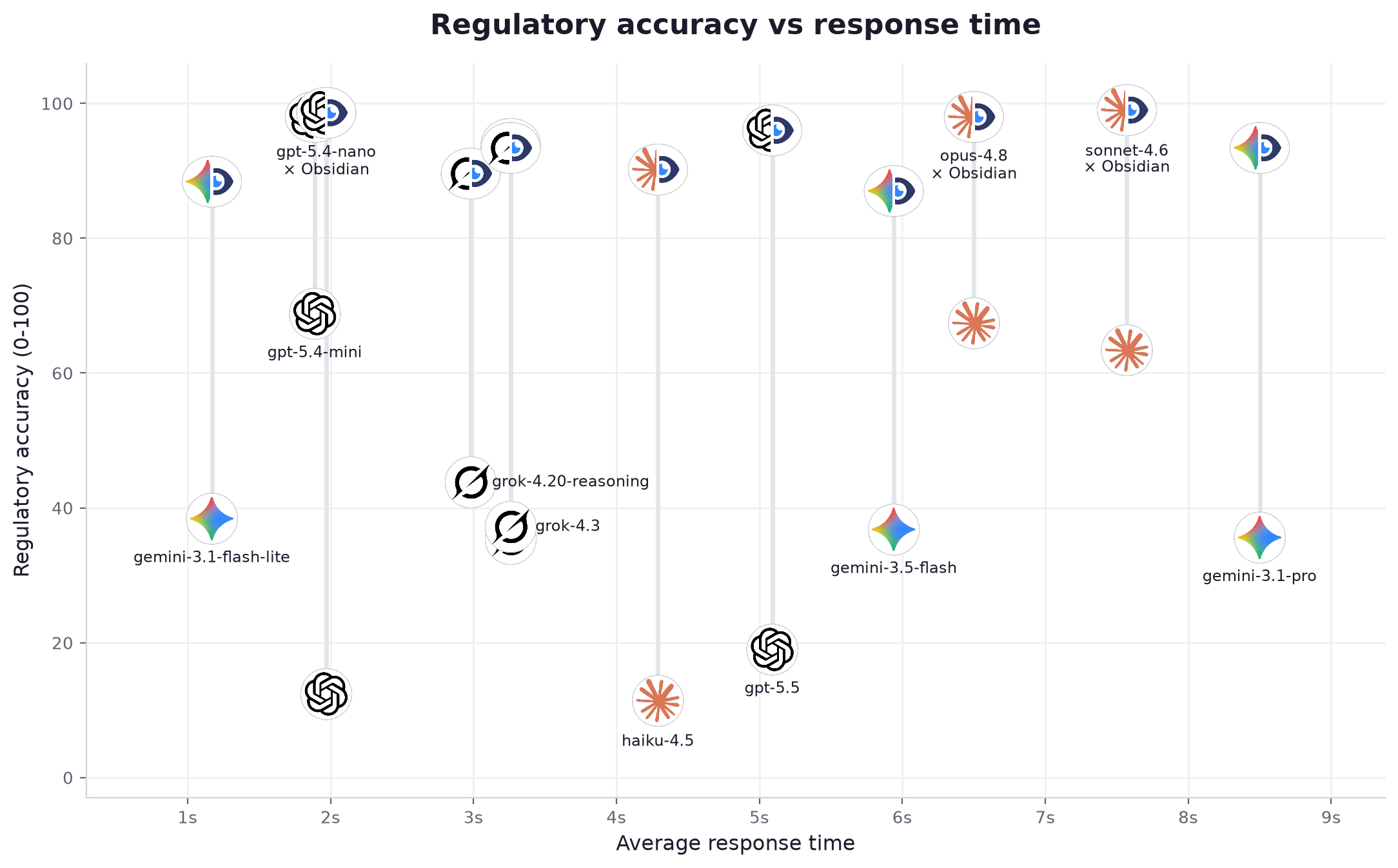
| 1 | gemini-3.1-flash-lite | light | 60.2 | 95.6 | +35.4 | 96% | 100% | 25% → 98% | 0.82s | 130 tok/s | $0.175 | $0.000264 | |
| 2 | gpt-5.4-mini | OpenAI | mid | 69.5 | 95.5 | +26.0 | 96% | 100% | 38% → 96% | 1.25s | 84 tok/s | $0.7 | $0.000966 |
| 3 | gpt-5.4-nano | OpenAI | light | 42.5 | 95.5 | +53.0 | 94% | 99% | 28% → 96% | 1.42s | 83 tok/s | $0.463 | $0.000551 |
| 4 | opus-4.8 | Anthropic | advanced | 67.6 | 95.2 | +27.6 | 96% | 100% | 24% → 89% | 4.86s | 69 tok/s | $10.0 | $0.024427 |
| 5 | gpt-5.5 | OpenAI | advanced | 49.8 | 94.4 | +44.6 | 96% | 100% | 44% → 96% | 4.89s | 42 tok/s | $11.25 | $0.0167 |
| 6 | sonnet-4.6 | Anthropic | mid | 67.1 | 94.3 | +27.2 | 96% | 100% | 24% → 81% | 7.89s | 46 tok/s | $6.0 | $0.012284 |
| 7 | haiku-4.5 | Anthropic | light | 43.6 | 93.5 | +49.9 | 96% | 100% | 21% → 88% | 2.85s | 75 tok/s | $2.0 | $0.003326 |
| 8 | grok-3-mini | xAI | light | 54.3 | 93.3 | +39.0 | 97% | 99% | 34% → 91% | 3.26s | 127 tok/s | $0.35 | $0.000822 |
| 9 | grok-4.20-reasoning | xAI | advanced | 65.0 | 93.1 | +28.1 | 94% | 99% | 28% → 93% | 2.82s | 222 tok/s | $6.0 | $0.016179 |
| 10 | grok-4.3 | xAI | mid | 56.4 | 93.1 | +36.7 | 95% | 99% | 32% → 93% | 3.21s | 126 tok/s | $1.562 | $0.003594 |
| 11 | gemini-3.5-flash | mid | 61.4 | 91.9 | +30.5 | 96% | 99% | 28% → 95% | 3.33s | 182 tok/s | $3.375 | $0.009259 | |
| 12 | gemini-3.1-pro | advanced | 64.2 | 91.7 | +27.5 | 92% | 99% | 33% → 97% | 6.09s | 108 tok/s | $6.0 | $0.017109 |
Pooled across every answer, a light-tier model connected to Obsidian beat every frontier model answering alone. The ungrounded remainder of connected answers is added context beyond the source, not fabricated references.
How we measured it
- 12 models from Anthropic, OpenAI, Google and xAI, across light, mid and advanced tiers.
- Hundreds of complex, precise regulatory tasks across ESG (CSRD, the ESRS, the EU Taxonomy, SFDR, the CSDDD, CBAM), chemicals (REACH, CLP, the UN GHS and the Stockholm, Basel and Minamata Conventions) and life sciences (the ISO and IEC medtech standards, ICH, IMDRF), each tied to its official tier-0 source. Tasks outside Obsidian's current coverage perimeter are set aside, so the score measures answer quality, not coverage breadth.
- Two conditions per task: the model alone, and the same model connected to Obsidian. Nothing else changes.
- A blind judge scores each answer against human-verified ground truth; grounded claims come from a separate per-claim check against the official source.
Turn your AI into the model in row one
Connect Obsidian to Claude, ChatGPT, Gemini or Cursor, and every regulatory answer comes back with its official source, date and legal status. Free tier, two-minute setup.
Explore the Obsidian data layerWhat this means
If you already work through an AI assistant, the takeaway is concrete: you do not need a more expensive model, and you do not need to settle for guesses. The assistant you use today, given verified regulatory data, answers with the precision of a specialist and the receipts of an auditor. The background is here too: why AI hallucinates on regulatory questions, what tier-0 regulatory data is, and the idea of agentic regulatory intelligence. The per-provider and per-industry results are broken out in the Claude, ChatGPT, ESG, chemicals and life sciences editions. To test it on your own questions, connect the Obsidian regulatory data layer.


