If you work in medical-device or pharma regulatory affairs and quality, one detail decides whether an answer is usable: the edition. ISO 13485, ISO 14971, ISO 14155, IEC 62304 and the ICH guidelines all get revised, and citing a superseded edition in a submission or an audit is not a small slip, it is a finding. Ask an AI which edition is current, what the latest good-clinical-practice revision changed, or which guidance covers AI and machine-learning devices, and it answers fluently with the edition it was trained on, which may have been withdrawn.
The models reason about the standards perfectly well. What fails them is reach: a general model cannot know which edition is in force today. Give it the current text, and it stops guessing.
That text is what Obsidian supplies, deep on the global life-sciences standards. We put the models through hundreds of complex tasks across the ISO and IEC medtech standards, the ICH guidelines and the IMDRF guidance, each handled alone and connected to Obsidian.
AI is inaccurate for life-sciences regulatory work
Alone, the models averaged 52 out of 100. Connect them to Obsidian and the average climbs to 96. The best pairing, gpt-5.5, reached 97.5. The models did not change between those two numbers. Only the data in front of them did.
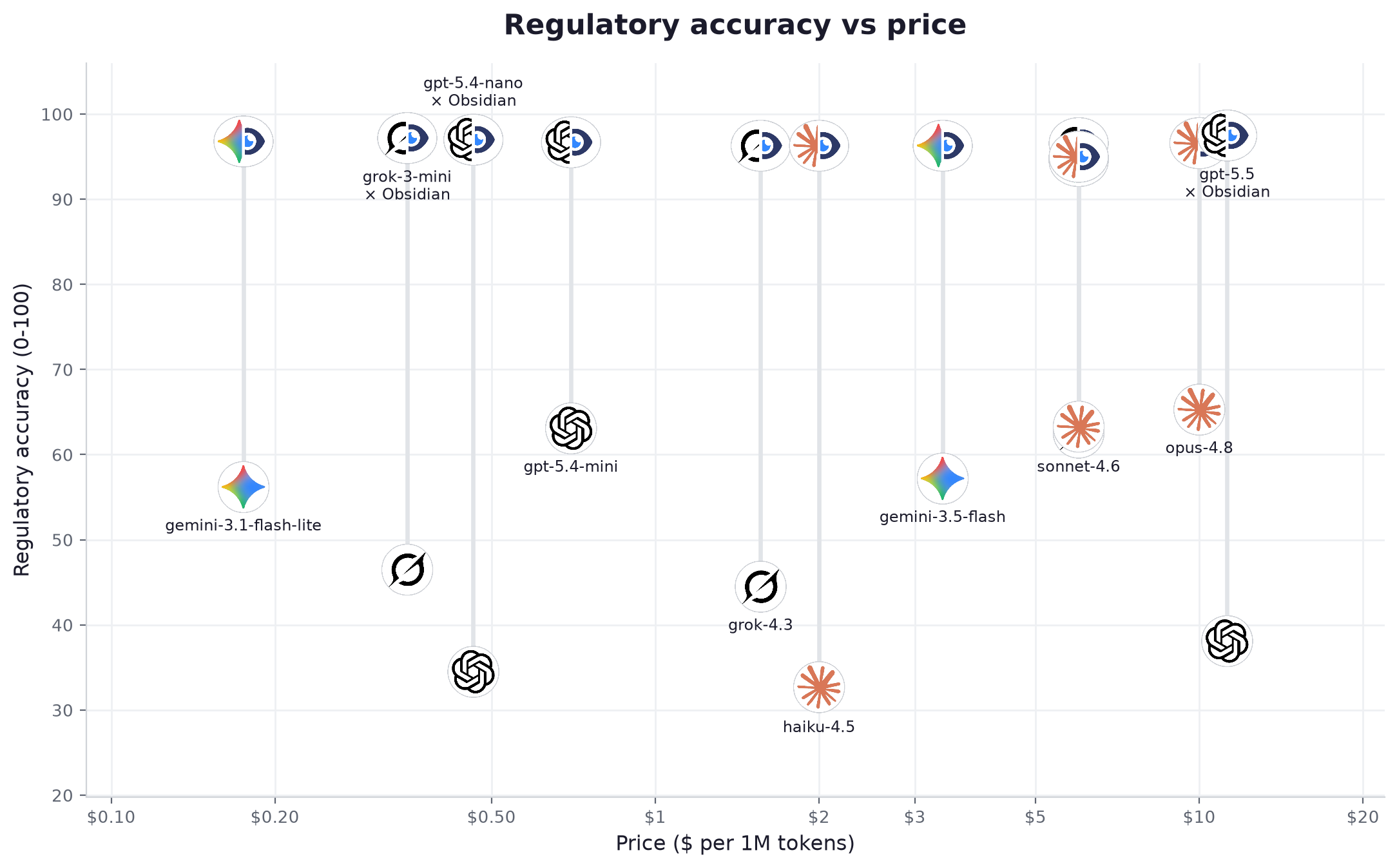
Life sciences is the sharpest case for a data layer anywhere in this benchmark: editions move constantly, and a model working from memory cites the one it learned rather than the one in force. That single gap is where a submission gets held up. gemini-3.1-flash-lite, at $0.175 per million tokens, climbs from 56 to 97 once connected, into the band of models many times its price. A light-tier model connected to Obsidian beat a frontier model answering alone in 16 of 16 head-to-head pairings on the life-sciences set.
AI cannot point you to the official standard
Here the edition is the answer. Connected to Obsidian, a response arrives with the standard, its current edition, the issuing body and a direct link. Alone, you get a plausible citation, often the wrong edition, to verify yourself. For a notified-body review or a regulatory submission, the difference between the current edition and a withdrawn one is the difference between a defensible file and a finding.
An answer with the tier-0 source attached is one you can forward to an auditor without re-checking it. That is the difference between a draft a model imagined and an obligation you can act on.
AI hallucinates
We broke every answer into its individual factual claims and checked each against the official source. The gap between the two grounded-claim numbers above is the dangerous kind of error removed on a field where a single wrong edition undermines a submission. The ungrounded remainder is added context, not invented references.
The full data, for the purists
Every model, both conditions. "Alone" is the model with no data layer; "with Obsidian" is the same model connected. Accuracy is a 0 to 100 score from a blind judge against human-verified ground truth. "Grounded claims" is the share of the answer's atomic factual claims that trace back to the official source, alone versus with Obsidian.
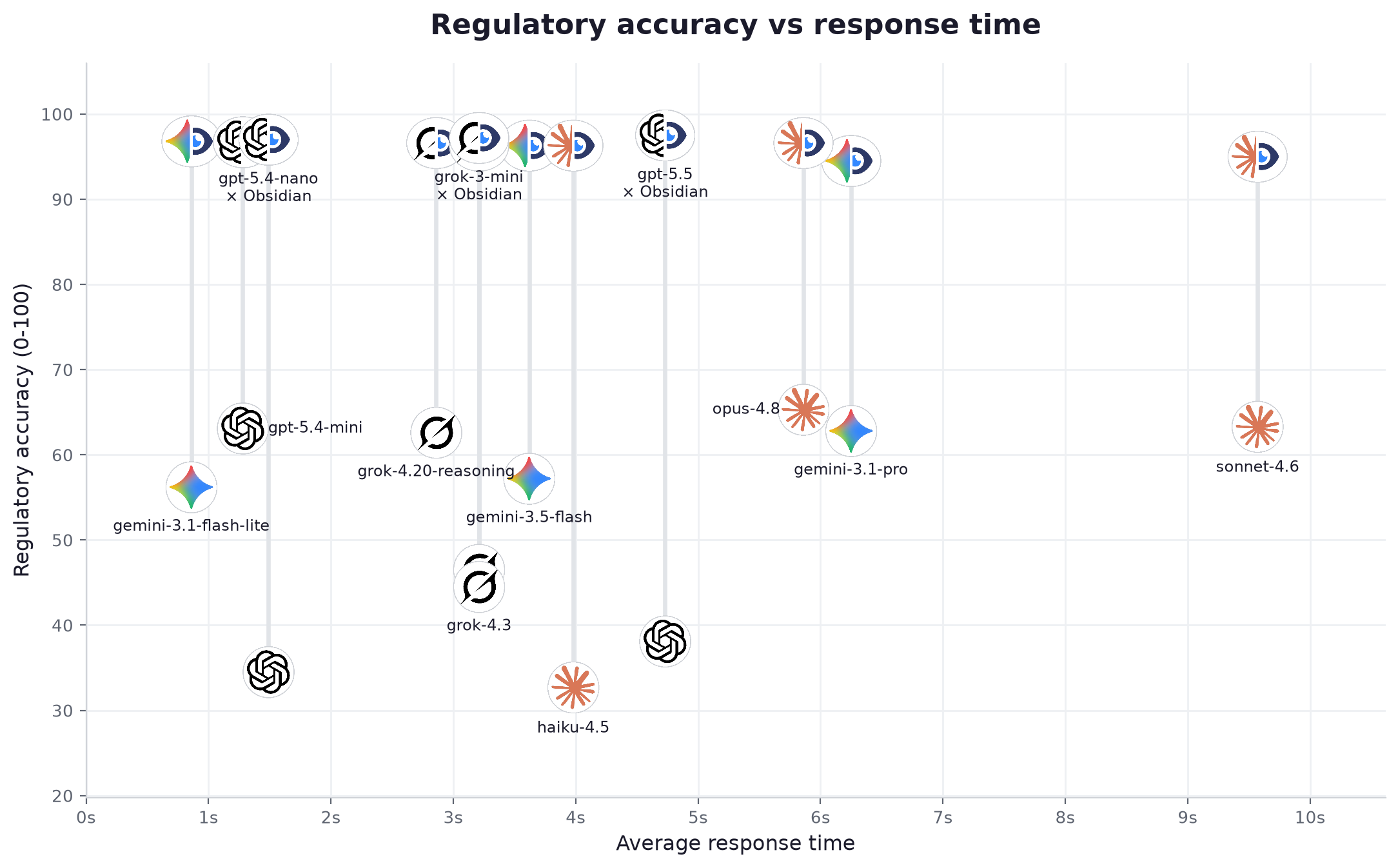
| # | Model | Provider | Tier | Acc. alone | Acc. + Obsidian | Lift | Cites source | Status correct | Grounded claims (alone → +Obs) | Latency | Speed | Price /1M | Cost / question |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gpt-5.5 | OpenAI | advanced | 38.1 | 97.5 | +59.4 | 96% | 100% | 42% → 98% | 4.73s | 49 tok/s | $11.25 | $0.026259 |
| 2 | grok-3-mini | xAI | light | 46.5 | 97.2 | +50.7 | 99% | 100% | 34% → 94% | 3.21s | 136 tok/s | $0.35 | $0.001342 |
| 3 | gpt-5.4-nano | OpenAI | light | 34.5 | 97.0 | +62.5 | 97% | 100% | 24% → 98% | 1.49s | 88 tok/s | $0.463 | $0.000922 |
| 4 | gemini-3.1-flash-lite | light | 56.2 | 96.8 | +40.6 | 98% | 100% | 30% → 98% | 0.86s | 139 tok/s | $0.175 | $0.000469 | |
| 5 | gpt-5.4-mini | OpenAI | mid | 63.1 | 96.7 | +33.6 | 97% | 100% | 38% → 95% | 1.28s | 87 tok/s | $0.7 | $0.001685 |
| 6 | grok-4.20-reasoning | xAI | advanced | 62.6 | 96.6 | +34.0 | 96% | 100% | 30% → 96% | 2.86s | 226 tok/s | $6.0 | $0.021106 |
| 7 | opus-4.8 | Anthropic | advanced | 65.3 | 96.6 | +31.3 | 96% | 100% | 28% → 93% | 5.86s | 69 tok/s | $10.0 | $0.039476 |
| 8 | gemini-3.5-flash | mid | 57.2 | 96.3 | +39.1 | 99% | 100% | 34% → 98% | 3.62s | 183 tok/s | $3.375 | $0.012549 | |
| 9 | grok-4.3 | xAI | mid | 44.5 | 96.3 | +51.8 | 98% | 100% | 32% → 97% | 3.21s | 132 tok/s | $1.562 | $0.005775 |
| 10 | haiku-4.5 | Anthropic | light | 32.7 | 96.3 | +63.6 | 98% | 100% | 22% → 90% | 3.98s | 64 tok/s | $2.0 | $0.005482 |
| 11 | sonnet-4.6 | Anthropic | mid | 63.3 | 95.0 | +31.7 | 96% | 100% | 26% → 85% | 9.57s | 42 tok/s | $6.0 | $0.019201 |
| 12 | gemini-3.1-pro | advanced | 62.8 | 94.5 | +31.7 | 92% | 100% | 42% → 98% | 6.25s | 107 tok/s | $6.0 | $0.020789 |
Life sciences shows the largest gap between a model working from memory and one reading the current standard, which is exactly where a maintained data layer earns its place.
How we measured it
- The full model set from Anthropic, OpenAI, Google and xAI.
- Hundreds of complex life-sciences tasks across the ISO and IEC medtech standards (quality, risk, clinical, software, biocompatibility), the ICH guidelines and the IMDRF guidance, each tied to its official source and current edition.
- Two conditions: the model alone, and connected to Obsidian.
- A blind judge scores each answer; grounded claims come from a separate per-claim check against the official source.
Put the right edition of every standard behind your AI
Connect Obsidian to the AI you already use and every standards answer comes back with the current edition and issuing body. Free tier, two-minute setup.
Explore the Obsidian data layerWhat this means
For medical-device and pharma regulatory and quality teams, the assistant you already use, given verified data, stops citing withdrawn editions and starts answering with the standard and edition that are actually in force, so a reviewer can rely on it in a submission. The background is here too: tier-0 regulatory data and agentic regulatory intelligence. The full cross-industry results are in the regulatory AI benchmark. To test it on your own questions, connect the Obsidian regulatory data layer.