Ask ChatGPT a regulatory question and the answer comes back fast and self-assured. Then you check it. The regulation number does not exist. The deadline it quotes passed two years ago. The "requirement" was a proposal that never became law. After enough of these, the verdict feels obvious: ChatGPT is not ready for regulatory work.
It is the wrong verdict. The GPT models people use every day are perfectly capable of regulatory reasoning. What fails them is not intelligence, it is reach. A general model answers from a frozen snapshot of the open web, with no way to open the actual text of a regulation or to know whether it is in force today. Give it that text, and it stops guessing.
That text is what Obsidian supplies: a verified, tier-0 regulatory data layer ChatGPT can query, returning the official wording, the current legal status, and a direct link to the source. We ran three GPT models, GPT-5.4-nano, GPT-5.4-mini, and GPT-5.5, through real, current regulatory questions, each answered twice. Once alone. Once connected to Obsidian.
ChatGPT is inaccurate for regulatory work
Alone, the three GPT models averaged 33 out of 100. That is the experience behind the complaint, and on those terms the complaint is fair. Connected to Obsidian, the same three averaged 98. Nothing about the models changed between those two numbers. Only the data in front of them did.
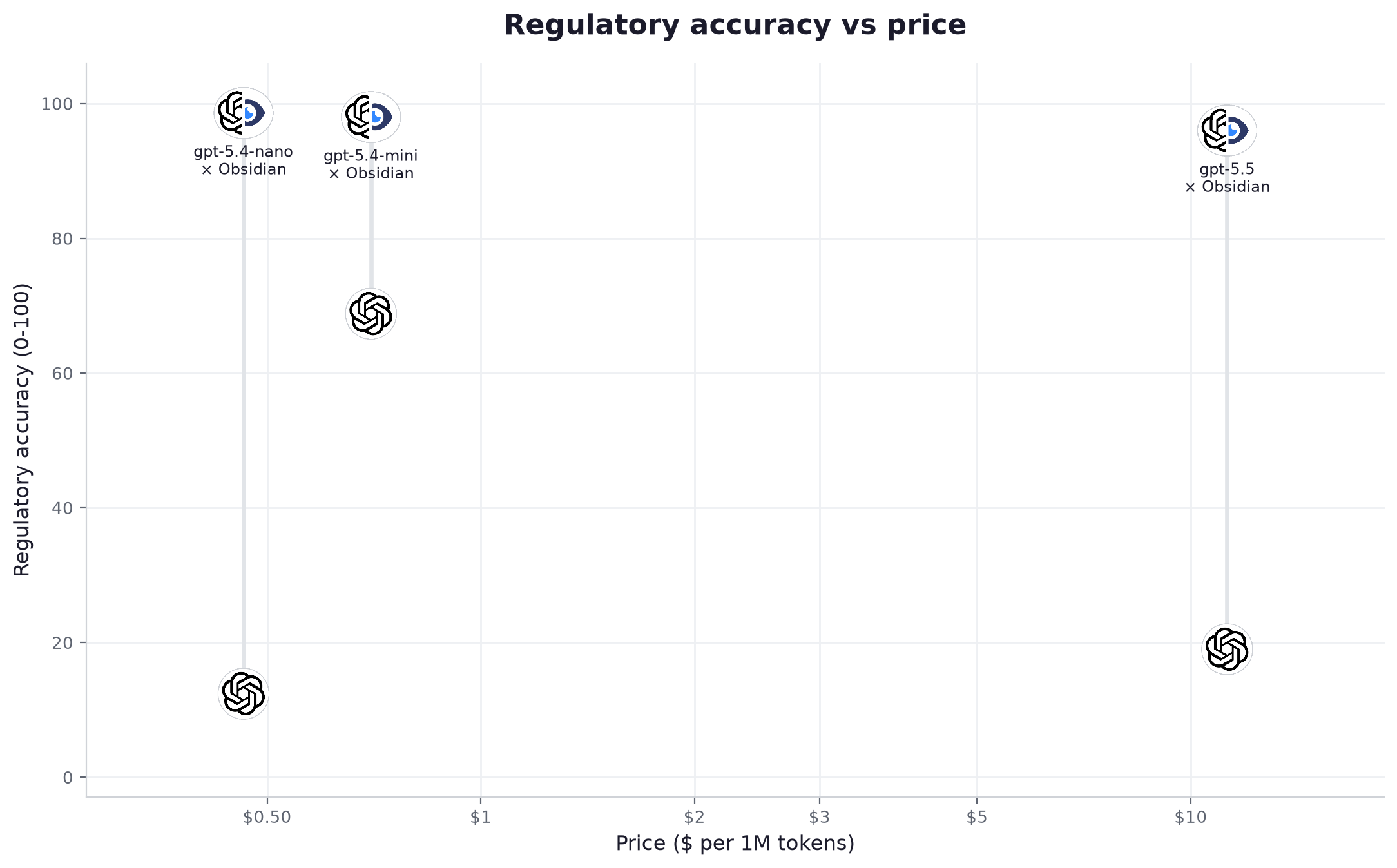
The standout is the smallest one. GPT-5.4-nano, at $0.46 per million tokens and under two seconds an answer, scores 12 alone and 98.6 connected, the highest of the three and twenty-five times cheaper than GPT-5.5. On regulation, the data layer outweighs the model size. You are not buying accuracy from a bigger GPT. You are handing the data to a small one.
ChatGPT cannot point you to the official source
Ask a GPT model alone for the instrument behind a rule and you get a plausible-looking citation you then have to go and verify yourself, assuming it exists. Connected to Obsidian, every GPT answer came back with the official source attached, cited correctly on every single question across all three models: the instrument, its exact reference, the jurisdiction, the legal status, and a direct link to the official document, often the source PDF itself.
An answer with the tier-0 source attached is one you can forward to an auditor without re-checking it. That is the difference between a draft a model imagined and an obligation you can act on.
ChatGPT hallucinates
We broke every answer into its individual factual claims and checked each against the official source. Alone, 47% of a GPT answer's claims held up. Connected to Obsidian, 100% of them did, across all three models, and none contradicted the official text. A database built for the model to read does not make it incapable of error, but here it removed the dangerous kind entirely: the confident statement with nothing behind it.
The full data, for the purists
Three GPT models, both conditions. "Alone" is the model with no data layer; "with Obsidian" is the same model connected. Accuracy is a 0 to 100 score from a blind judge against human-verified ground truth. "Grounded claims" is the share of the answer's atomic factual claims that trace back to the official source, alone versus with Obsidian.
| # | Model | Tier | Acc. alone | Acc. + Obsidian | Lift | Cites source | Status correct | Grounded claims (alone → +Obs) | Latency | Speed | Price /1M | Cost / question |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
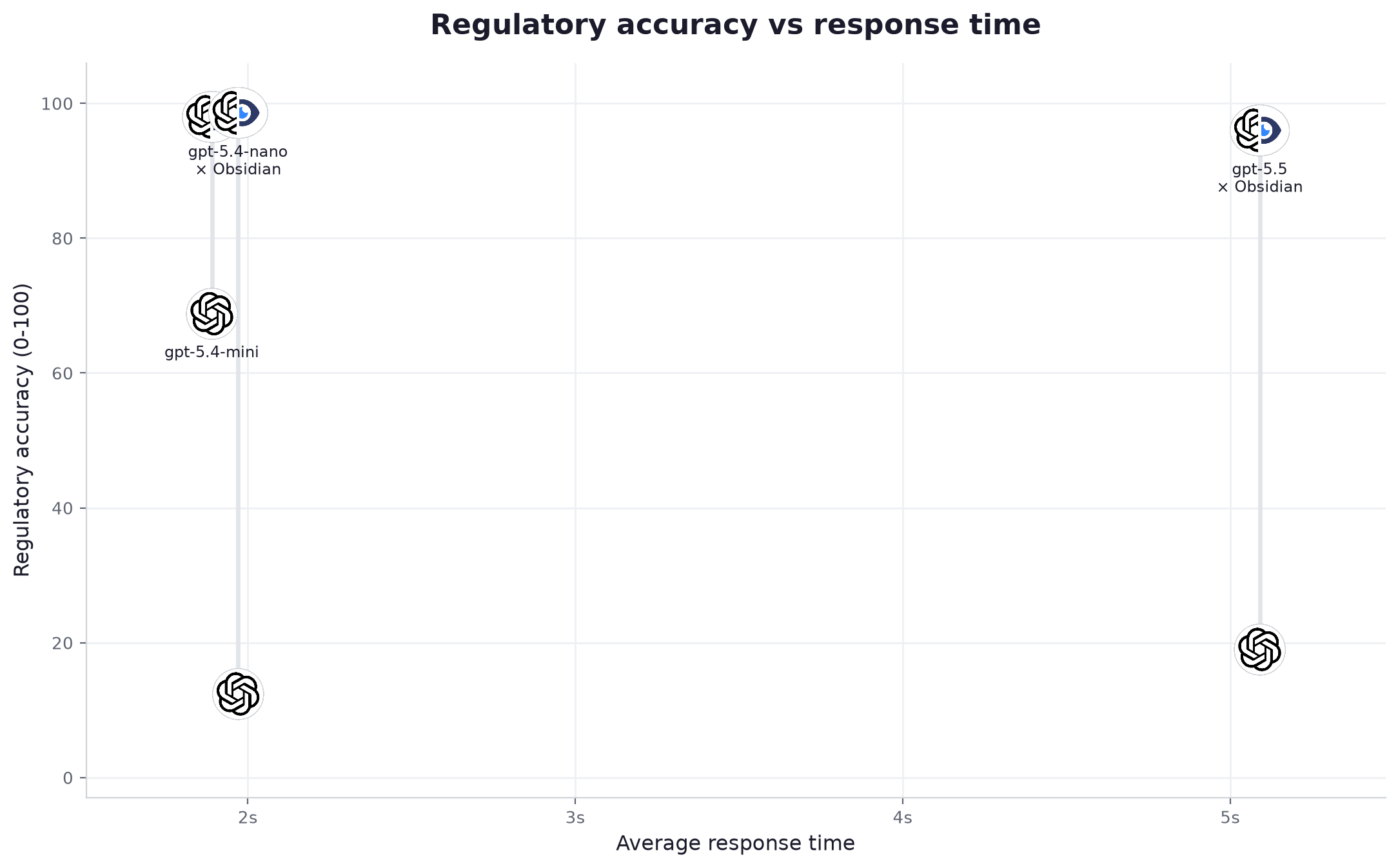
| 1 | gpt-5.4-nano | light | 12.4 | 98.6 | +86.2 | 100% | 100% | 30% → 100% | 2.0s | 107 tok/s | $0.46 | $0.008 |
| 2 | gpt-5.4-mini | mid | 68.8 | 98.0 | +29.2 | 100% | 100% | 57% → 100% | 1.9s | 96 tok/s | $0.70 | $0.008 |
| 3 | gpt-5.5 | advanced | 19.0 | 96.0 | +77.0 | 100% | 100% | 50% → 100% | 5.1s | 58 tok/s | $11.25 | $0.024 |
The questions are five current ESG cases, each in a different jurisdiction (Belgium, France, Italy, the Netherlands, the United States), answered by each model alone and with Obsidian, then scored by a blind judge against human-verified ground truth tied to the official source. This first run is a five-question pilot; a full-scale benchmark across more questions and domains is in progress, published the same way, every number reproducible.
Make ChatGPT the model in row one
Connect Obsidian to ChatGPT and every regulatory answer comes back with its official source, date, and legal status. Free tier, two-minute setup.
Explore the Obsidian data layerWhat this means if you run regulatory work through ChatGPT
You do not need a bigger model, and you do not need to settle for guesses. The GPT you already use, given verified regulatory data, answers with the precision of a specialist and the receipts of an auditor, often for less than a cent a question. The background is here too: why AI hallucinates on regulatory questions, what tier-0 regulatory data is, and the idea of agentic regulatory intelligence. To test it on your own questions, connect the Obsidian regulatory data layer. The full cross-provider results are in the regulatory AI benchmark.