Haga una pregunta regulatoria a una IA: la respuesta llega rápida, fluida y segura de sí misma. Luego la comprueba: un número de reglamento que no existe, una edición dos versiones desfasada, una regla citada como vinculante cuando todavía es un borrador. Tras varias experiencias así, el veredicto parece obvio: la IA no está lista para el trabajo regulatorio.
Es el veredicto equivocado. Los modelos que todo el mundo ya utiliza son perfectamente capaces de razonamiento regulatorio. Lo que les falla no es la inteligencia, es el alcance: un modelo generalista responde a partir de una instantánea congelada de la web abierta, sin forma de abrir el texto real de un reglamento ni de saber si hoy está en vigor. Entréguele ese texto, y deja de adivinar.
Ese texto es lo que aporta Obsidian: una capa de datos regulatorios verificados, de nivel tier-0, construida para que una IA la consulte. Para medir lo que cambia, sometimos 12 modelos de uso extendido a cientos de tareas regulatorias complejas y precisas en ESG, química y ciencias de la vida, cada una resuelta dos veces. Una vez solo. Una vez conectado a Obsidian. Los tres números de abajo cuentan toda la historia.
La IA es imprecisa para el trabajo regulatorio
Solos, los doce modelos promediaron 58 sobre 100. Conéctelos a Obsidian y la media sube a 94. Los modelos no cambiaron entre esos dos números. Solo cambiaron los datos puestos delante de ellos. La mejora se mantiene en todos los ámbitos: la química pasa de 53 a 95, las ciencias de la vida de 52 a 96, el ESG de 72 a 90. Ya no compra la precisión con el modelo; se la entrega con los datos.
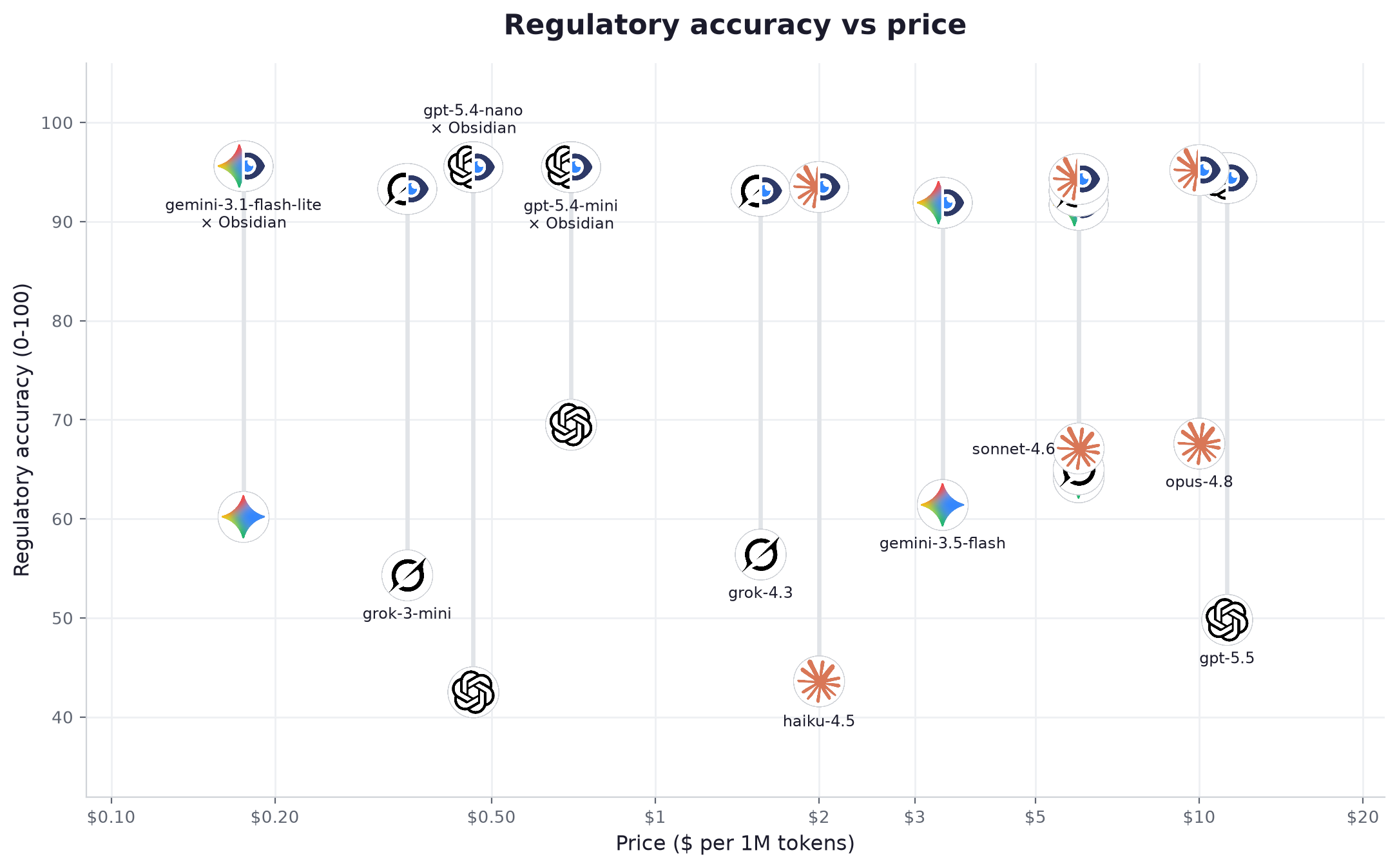
La señal más clara está en la parte baja del eje de precios. gemini-3.1-flash-lite, a $0.175 por millón de tokens, sube de 60 a 96 una vez conectado: la mejor puntuación de la tabla, por delante de modelos que cuestan muchas veces más. Un modelo de gama ligera conectado a Obsidian venció a un modelo de frontera respondiendo solo en 16 de 16 enfrentamientos directos. En el trabajo regulatorio, el alcance vence a la capacidad bruta, y el alcance es exactamente lo que añade una capa de datos.
La IA no puede señalarle la fuente oficial
La precisión es solo la mitad del asunto. Una respuesta conectada no se limita a acertar la regla correcta, muestra sus pruebas: el instrumento, su referencia y edición exactas, el estado jurídico y un enlace directo al documento oficial, a menudo el PDF de origen. Un modelo sin conectar le da una cita de apariencia plausible que luego tiene que verificar usted mismo, si es que existe. La respuesta conectada llega ya comprobable, que es justo lo que un equipo de cumplimiento necesita.
Una respuesta con su fuente tier-0 adjunta es una respuesta que puede reenviar a un auditor sin volver a comprobarla. Esa es la diferencia entre un borrador imaginado por un modelo y una obligación sobre la que puede actuar.
La IA alucina
Para medirlo con precisión, descompusimos cada respuesta en sus afirmaciones factuales individuales y comprobamos cada una contra la fuente oficial, en lugar de fiarnos de un único veredicto de sí o no. La brecha entre los dos números de fundamentación de arriba es el tipo de error peligroso ya eliminado: la afirmación segura de sí misma sin nada detrás. La parte no fundamentada restante no son citas inventadas, es contexto adicional que el modelo añade alrededor de la fuente, y por eso ningún modelo alcanza un 100 limpio.
Los datos completos, para los puristas
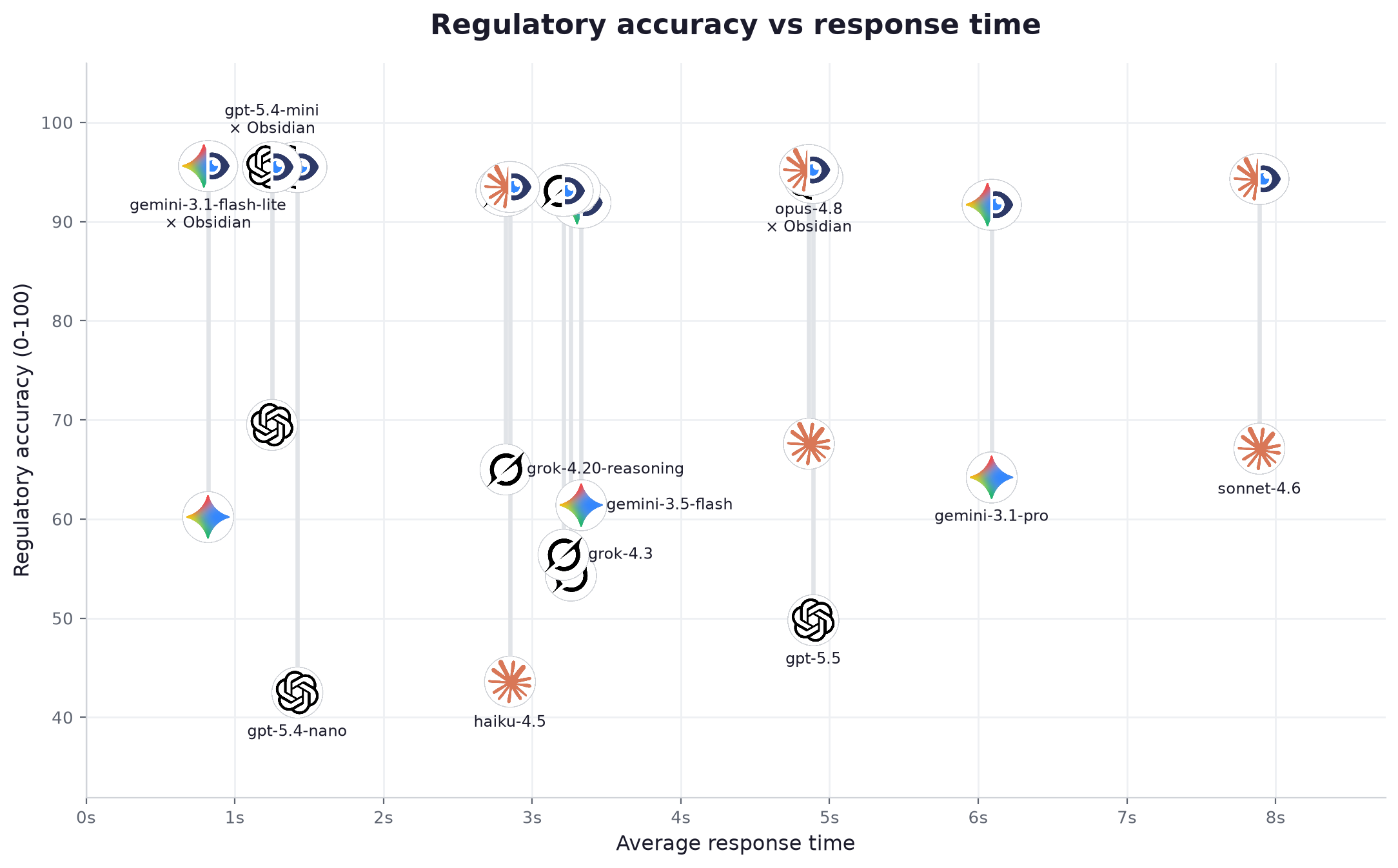
Cada modelo, en ambas condiciones. "Solo" es el modelo sin capa de datos; "con Obsidian" es el mismo modelo conectado. La precisión es una puntuación de 0 a 100 otorgada por un juez ciego contra una verdad de referencia verificada por personas. "Afirmaciones fundamentadas" es la proporción de las afirmaciones factuales atómicas de la respuesta que se remontan a la fuente oficial, solo frente a con Obsidian.
| # | Modelo | Proveedor | Gama | Prec. solo | Prec. + Obsidian | Mejora | Cita la fuente | Estado correcto | Afirmaciones fundamentadas (solo → +Obs) | Latencia | Velocidad | Precio /1M | Coste / pregunta |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gemini-3.1-flash-lite | ligera | 60.2 | 95.6 | +35.4 | 96% | 100% | 25% → 98% | 0.82s | 130 tok/s | $0.175 | $0.000264 | |
| 2 | gpt-5.4-mini | OpenAI | media | 69.5 | 95.5 | +26.0 | 96% | 100% | 38% → 96% | 1.25s | 84 tok/s | $0.7 | $0.000966 |
| 3 | gpt-5.4-nano | OpenAI | ligera | 42.5 | 95.5 | +53.0 | 94% | 99% | 28% → 96% | 1.42s | 83 tok/s | $0.463 | $0.000551 |
| 4 | opus-4.8 | Anthropic | avanzada | 67.6 | 95.2 | +27.6 | 96% | 100% | 24% → 89% | 4.86s | 69 tok/s | $10.0 | $0.024427 |
| 5 | gpt-5.5 | OpenAI | avanzada | 49.8 | 94.4 | +44.6 | 96% | 100% | 44% → 96% | 4.89s | 42 tok/s | $11.25 | $0.0167 |
| 6 | sonnet-4.6 | Anthropic | media | 67.1 | 94.3 | +27.2 | 96% | 100% | 24% → 81% | 7.89s | 46 tok/s | $6.0 | $0.012284 |
| 7 | haiku-4.5 | Anthropic | ligera | 43.6 | 93.5 | +49.9 | 96% | 100% | 21% → 88% | 2.85s | 75 tok/s | $2.0 | $0.003326 |
| 8 | grok-3-mini | xAI | ligera | 54.3 | 93.3 | +39.0 | 97% | 99% | 34% → 91% | 3.26s | 127 tok/s | $0.35 | $0.000822 |
| 9 | grok-4.20-reasoning | xAI | avanzada | 65.0 | 93.1 | +28.1 | 94% | 99% | 28% → 93% | 2.82s | 222 tok/s | $6.0 | $0.016179 |
| 10 | grok-4.3 | xAI | media | 56.4 | 93.1 | +36.7 | 95% | 99% | 32% → 93% | 3.21s | 126 tok/s | $1.562 | $0.003594 |
| 11 | gemini-3.5-flash | media | 61.4 | 91.9 | +30.5 | 96% | 99% | 28% → 95% | 3.33s | 182 tok/s | $3.375 | $0.009259 | |
| 12 | gemini-3.1-pro | avanzada | 64.2 | 91.7 | +27.5 | 92% | 99% | 33% → 97% | 6.09s | 108 tok/s | $6.0 | $0.017109 |
Agrupando todas las respuestas, un modelo de gama ligera conectado a Obsidian venció a todos los modelos de frontera respondiendo solos. La parte no fundamentada de las respuestas conectadas es contexto añadido más allá de la fuente, no referencias fabricadas.
Cómo lo medimos
- 12 modelos de Anthropic, OpenAI, Google y xAI, repartidos entre las gamas ligera, media y avanzada.
- Cientos de tareas regulatorias complejas y precisas en ESG (CSRD, los ESRS, la taxonomía de la UE, SFDR, la CSDDD, el CBAM), química (REACH, CLP, el SGA de la ONU y los convenios de Estocolmo, Basilea y Minamata) y ciencias de la vida (las normas medtech ISO e IEC, ICH, IMDRF), cada una ligada a su fuente oficial tier-0. Las tareas fuera del perímetro de cobertura actual de Obsidian se dejan de lado, de modo que la puntuación mide la calidad de las respuestas, no la amplitud de la cobertura.
- Dos condiciones por tarea: el modelo solo, y el mismo modelo conectado a Obsidian. Nada más cambia.
- Un juez ciego puntúa cada respuesta contra una verdad de referencia verificada por personas; las afirmaciones fundamentadas provienen de una comprobación separada, afirmación por afirmación, contra la fuente oficial.
Convierta su IA en el modelo de la primera fila
Conecte Obsidian a Claude, ChatGPT, Gemini o Cursor, y cada respuesta regulatoria vuelve con su fuente oficial, su fecha y su estado jurídico. Plan gratuito, configuración en dos minutos.
Descubra la capa de datos ObsidianQué significa esto
Si ya trabaja a través de un asistente de IA, la conclusión es concreta: no necesita un modelo más caro, y no tiene que conformarse con conjeturas. El asistente que usa hoy, alimentado con datos regulatorios verificados, responde con la precisión de un especialista y los comprobantes de un auditor. El trasfondo también está aquí: por qué la IA alucina con las preguntas regulatorias, qué son los datos regulatorios tier-0, y la idea de la inteligencia regulatoria agéntica. Los resultados por proveedor y por sector se detallan en las ediciones Claude, ChatGPT, ESG, química y ciencias de la vida. Para probarlo con sus propias preguntas, conecte la capa de datos regulatorios Obsidian.