Ponete una domanda regolatoria a un'IA: la risposta arriva rapida, fluida e sicura di sé. Poi la verificate: un numero di regolamento che non esiste, un'edizione indietro di due versioni, una regola citata come vincolante quando è ancora una bozza. Dopo qualche esperienza del genere, il verdetto sembra ovvio: l'IA non è pronta per il lavoro regolatorio.
È il verdetto sbagliato. I modelli che tutti usano già sono perfettamente capaci di ragionamento regolatorio. Ciò che manca loro non è l'intelligenza, è l'accesso: un modello generalista risponde a partire da un'istantanea congelata del web aperto, senza alcun modo di aprire il testo reale di un regolamento né di sapere se oggi è in vigore. Dategli quel testo, e smette di tirare a indovinare.
Quel testo è ciò che fornisce Obsidian: un layer di dati regolatori verificati, di livello tier-0, costruito per essere interrogato da un'IA. Per misurare che cosa cambia, abbiamo sottoposto 12 modelli di largo uso a centinaia di compiti regolatori complessi e precisi su ESG, chimica e scienze della vita, ciascuno affrontato due volte. Una volta da solo. Una volta connesso a Obsidian. I tre numeri qui sotto raccontano tutta la storia.
L'IA è imprecisa per il lavoro regolatorio
Da soli, i dodici modelli hanno ottenuto in media 58 su 100. Connetteteli a Obsidian e la media sale a 94. I modelli non sono cambiati tra questi due numeri. Sono cambiati solo i dati messi davanti a loro. Il guadagno regge in ogni dominio: la chimica passa da 53 a 95, le scienze della vita da 52 a 96, l'ESG da 72 a 90. Non state più comprando l'accuratezza dal modello; gliela state consegnando con i dati.
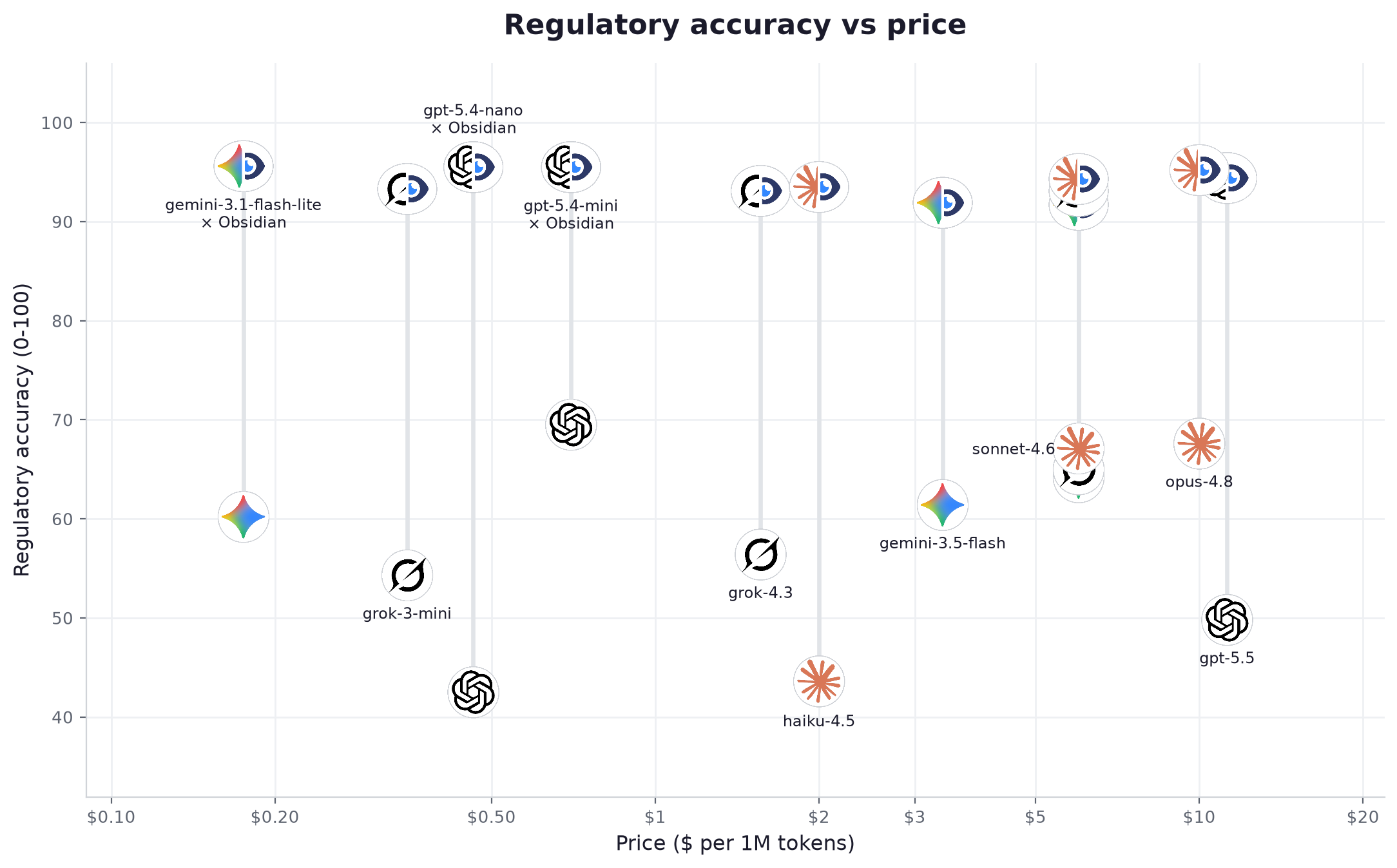
Il segnale più chiaro sta in fondo all'asse dei prezzi. gemini-3.1-flash-lite, a $0.175 per milione di token, sale da 60 a 96 una volta connesso: il punteggio più alto della tabella, davanti a modelli che costano molte volte di più. Un modello di fascia leggera connesso a Obsidian ha battuto un modello di frontiera che rispondeva da solo in 16 confronti diretti su 16. Nel lavoro regolatorio, l'accesso conta più della potenza pura, e l'accesso è esattamente ciò che un layer di dati aggiunge.
L'IA non sa indicarvi la fonte ufficiale
L'accuratezza è solo metà della questione. Una risposta connessa non si limita a centrare la regola giusta, mostra le sue prove: lo strumento, il suo riferimento e la sua edizione esatti, lo stato giuridico e un link diretto al documento ufficiale, spesso il PDF di origine. Un modello nudo vi dà una citazione dall'aria plausibile che dovete poi verificare voi stessi, ammesso che esista. La risposta connessa arriva già verificabile, ed è esattamente ciò di cui un team compliance ha davvero bisogno.
Una risposta con la fonte tier-0 allegata è una risposta che potete inoltrare a un auditor senza ricontrollarla. È la differenza tra una bozza immaginata da un modello e un obbligo su cui potete agire.
L'IA ha le allucinazioni
Per misurarlo con precisione abbiamo scomposto ogni risposta nelle sue singole affermazioni fattuali e verificato ciascuna rispetto alla fonte ufficiale, invece di fidarci di un unico verdetto binario. Il divario tra i due numeri di fondatezza qui sopra è l'errore più pericoloso, ora eliminato: l'affermazione sicura di sé che non poggia su nulla. La quota non fondata rimanente non è fatta di citazioni inventate, è contesto aggiuntivo che il modello inserisce attorno alla fonte, ed è per questo che nessun modello raggiunge un 100 netto.
I dati completi, per i puristi
Ogni modello, in entrambe le condizioni. "Da solo" è il modello senza layer di dati; "con Obsidian" è lo stesso modello connesso. L'accuratezza è un punteggio da 0 a 100 assegnato da un giudice in cieco rispetto a una verità di riferimento verificata da persone. "Affermazioni fondate" è la quota delle affermazioni fattuali atomiche della risposta che risalgono alla fonte ufficiale, da solo e poi con Obsidian.
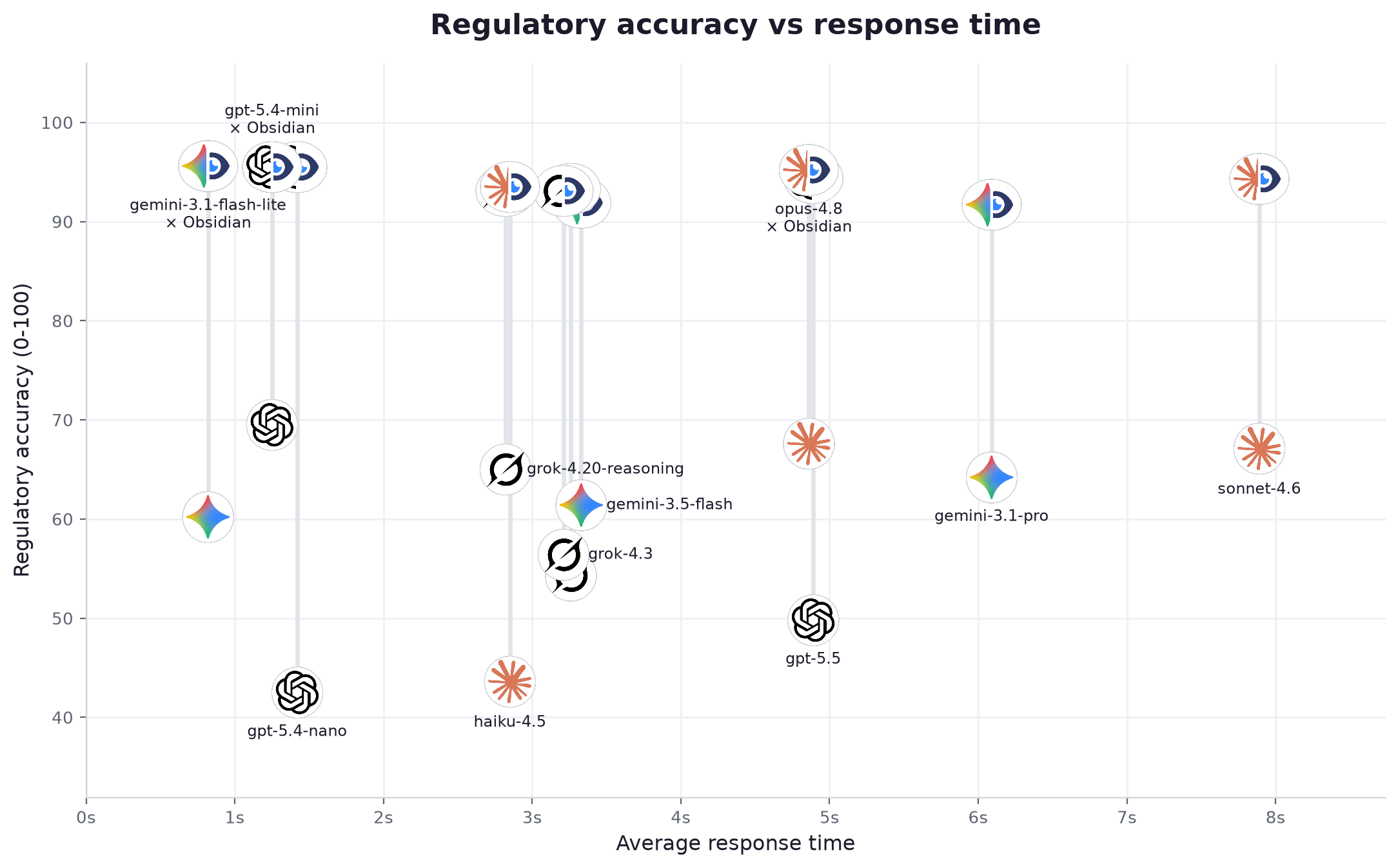
| # | Modello | Fornitore | Fascia | Acc. da solo | Acc. + Obsidian | Guadagno | Cita la fonte | Stato corretto | Affermazioni fondate (da solo → +Obs) | Latenza | Velocità | Prezzo /1M | Costo / domanda |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | gemini-3.1-flash-lite | leggera | 60.2 | 95.6 | +35.4 | 96% | 100% | 25% → 98% | 0.82s | 130 tok/s | $0.175 | $0.000264 | |
| 2 | gpt-5.4-mini | OpenAI | intermedia | 69.5 | 95.5 | +26.0 | 96% | 100% | 38% → 96% | 1.25s | 84 tok/s | $0.7 | $0.000966 |
| 3 | gpt-5.4-nano | OpenAI | leggera | 42.5 | 95.5 | +53.0 | 94% | 99% | 28% → 96% | 1.42s | 83 tok/s | $0.463 | $0.000551 |
| 4 | opus-4.8 | Anthropic | avanzata | 67.6 | 95.2 | +27.6 | 96% | 100% | 24% → 89% | 4.86s | 69 tok/s | $10.0 | $0.024427 |
| 5 | gpt-5.5 | OpenAI | avanzata | 49.8 | 94.4 | +44.6 | 96% | 100% | 44% → 96% | 4.89s | 42 tok/s | $11.25 | $0.0167 |
| 6 | sonnet-4.6 | Anthropic | intermedia | 67.1 | 94.3 | +27.2 | 96% | 100% | 24% → 81% | 7.89s | 46 tok/s | $6.0 | $0.012284 |
| 7 | haiku-4.5 | Anthropic | leggera | 43.6 | 93.5 | +49.9 | 96% | 100% | 21% → 88% | 2.85s | 75 tok/s | $2.0 | $0.003326 |
| 8 | grok-3-mini | xAI | leggera | 54.3 | 93.3 | +39.0 | 97% | 99% | 34% → 91% | 3.26s | 127 tok/s | $0.35 | $0.000822 |
| 9 | grok-4.20-reasoning | xAI | avanzata | 65.0 | 93.1 | +28.1 | 94% | 99% | 28% → 93% | 2.82s | 222 tok/s | $6.0 | $0.016179 |
| 10 | grok-4.3 | xAI | intermedia | 56.4 | 93.1 | +36.7 | 95% | 99% | 32% → 93% | 3.21s | 126 tok/s | $1.562 | $0.003594 |
| 11 | gemini-3.5-flash | intermedia | 61.4 | 91.9 | +30.5 | 96% | 99% | 28% → 95% | 3.33s | 182 tok/s | $3.375 | $0.009259 | |
| 12 | gemini-3.1-pro | avanzata | 64.2 | 91.7 | +27.5 | 92% | 99% | 33% → 97% | 6.09s | 108 tok/s | $6.0 | $0.017109 |
Considerando tutte le risposte insieme, un modello di fascia leggera connesso a Obsidian ha battuto ogni modello di frontiera che rispondeva da solo. La parte non fondata delle risposte connesse è contesto aggiunto oltre la fonte, non riferimenti fabbricati.
Come abbiamo misurato
- 12 modelli di Anthropic, OpenAI, Google e xAI, distribuiti tra le fasce leggera, intermedia e avanzata.
- Centinaia di compiti regolatori complessi e precisi su ESG (CSRD, gli ESRS, la tassonomia UE, SFDR, la CSDDD, il CBAM), chimica (REACH, CLP, il GHS dell'ONU e le convenzioni di Stoccolma, Basilea e Minamata) e scienze della vita (le norme medtech ISO e IEC, ICH, IMDRF), ciascuno legato alla sua fonte ufficiale tier-0. I compiti fuori dall'attuale perimetro di copertura di Obsidian sono messi da parte, così il punteggio misura la qualità delle risposte, non l'ampiezza della copertura.
- Due condizioni per compito: il modello da solo, e lo stesso modello connesso a Obsidian. Nient'altro cambia.
- Un giudice in cieco valuta ogni risposta rispetto a una verità di riferimento verificata da persone; le affermazioni fondate provengono da una verifica separata, affermazione per affermazione, rispetto alla fonte ufficiale.
Trasformate la vostra IA nel modello della prima riga
Connettete Obsidian a Claude, ChatGPT, Gemini o Cursor, e ogni risposta regolatoria torna con la sua fonte ufficiale, la data e lo stato giuridico. Piano gratuito, configurazione in due minuti.
Scoprite il layer di dati ObsidianChe cosa significa
Se lavorate già attraverso un assistente IA, la conclusione è concreta: non vi serve un modello più costoso, e non dovete accontentarvi di congetture. L'assistente che usate oggi, alimentato con dati regolatori verificati, risponde con la precisione di uno specialista e le prove di un auditor. Anche il contesto è qui: perché l'IA ha le allucinazioni sulle domande regolatorie, che cosa sono i dati regolatori tier-0, e l'idea di intelligence regolatoria agentica. I risultati per fornitore e per settore sono approfonditi nelle edizioni Claude, ChatGPT, ESG, chimica e scienze della vita. Per metterlo alla prova sulle vostre domande, connettete il layer di dati regolatori Obsidian.